





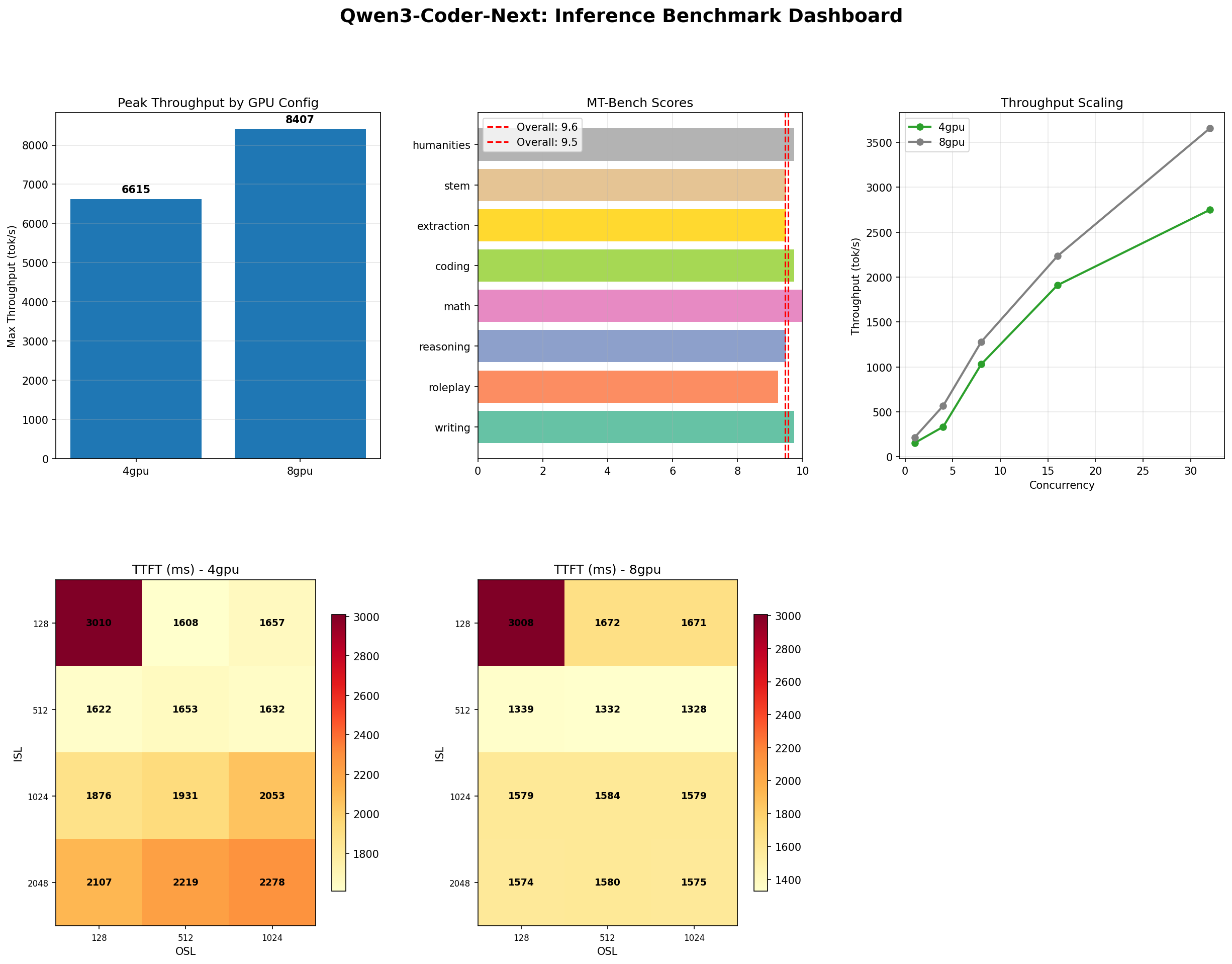
Build vs Buy
Llama 3 70B 1M Context chatbot, 1B tokens / month
Two cost paths for the same workload: rent the API per-token from the cheapest provider, or rent 2× H100 PCIe 24×7 and serve it yourself.
API (cheapest provider)$740/mo
Self-host (2× H100 PCIe)$3.3k/mo
$2.6kspent extra/mo · -352% pricier to self-host