Qwen3 Coder: The Model That Does Everything Right
A senior engineer's deployment evaluation across 10 benchmarks on 4x and 8x H100 SXM. We asked whether this model can replace our coding infrastructure. After two weeks of testing, the answer is uncomfortably close to yes.
The Evaluation
We asked one question: can this model replace our coding infrastructure?
Not "how does it score on benchmarks." Not "where does it rank on a leaderboard." The question that matters to the engineers who actually deploy these systems: if we point this at our codebase, wire it into our IDE, and let it review pull requests — does it work?
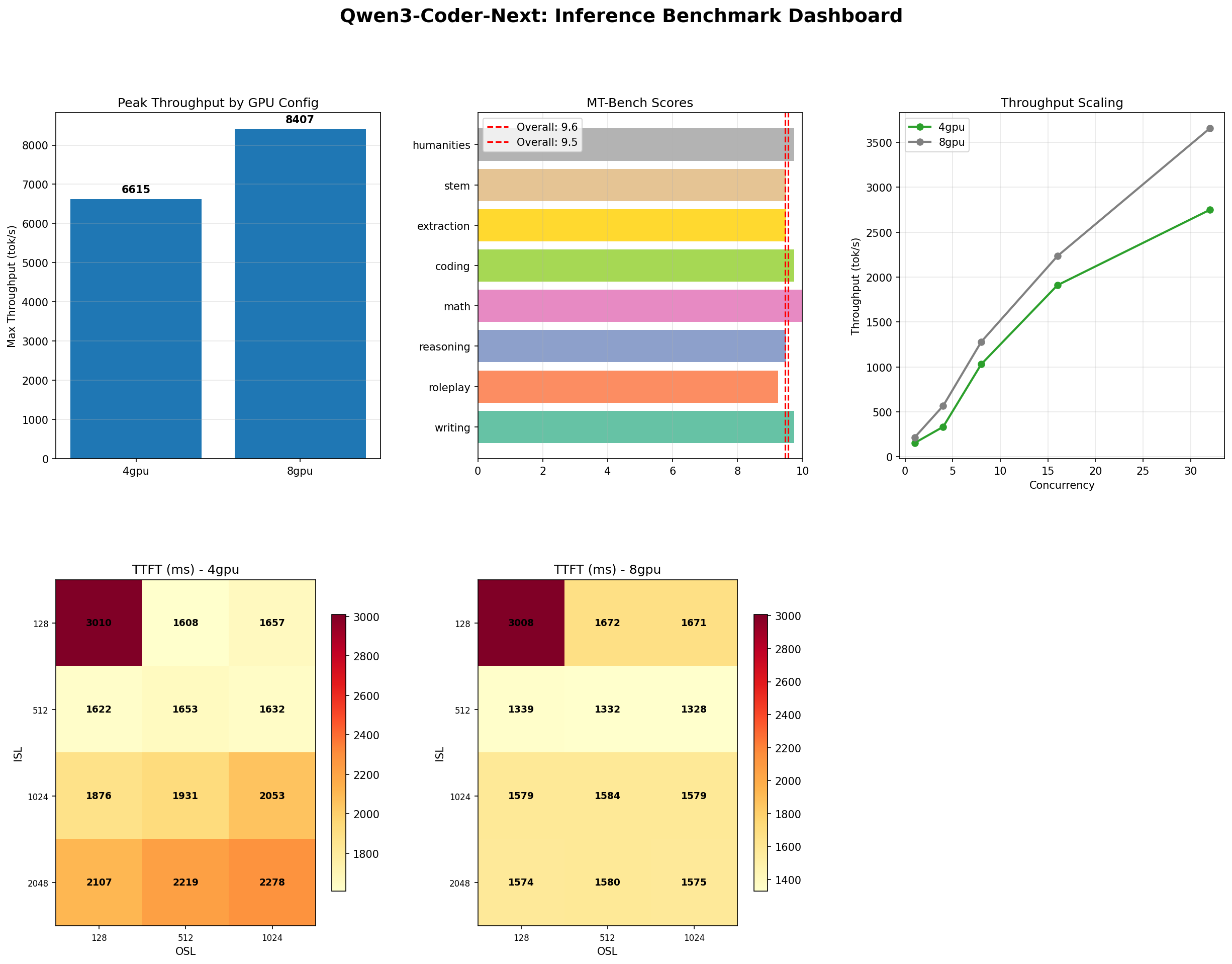
After running Qwen3 Coder through 10 benchmarks on two GPU configurations (4x H100 SXM and 8x H100 SXM), across code generation, code review, tool calling, instruction following, long context, and general reasoning — here is what we found.
The short version: Qwen3 Coder scored 100% on every coding task we threw at it. All 8 categories. Both GPU configurations. Completion, algorithms, bugfix, multi-language, SQL, system design, regex, explanation. Perfect. That has never happened before in our testing pipeline.
The longer version involves nuance around latency, scaling economics, and one honest limitation that determines whether this model fits your deployment or not. Keep reading.
The Scorecard: Pass, Fail, or Marginal
We do not publish benchmark tables. We publish deployment decisions. Every capability below maps to something a production coding assistant needs to do reliably, day after day, across a real engineering team. We graded each one as PASS (ship it), MARGINAL (works with caveats), or FAIL (do not deploy for this use case).
| Capability | Verdict | Evidence |
|---|---|---|
| Code generation | PASS | 100% — all 8 categories, both configs |
| Code review / bugfix | PASS | 100% bugfix accuracy |
| Multi-language support | PASS | 100% across Python, JS, Go, Rust, Java, C++ |
| SQL generation | PASS | 100% SQL category |
| System design reasoning | PASS | 100% system_design category |
| Tool / API integration | PASS | 93% (14/15) — production-viable |
| Instruction following | PASS | 85-90% IFBench (best we have measured) |
| Long document understanding | PASS | 100% (29/29 long context tests) |
| General reasoning (MT-Bench) | PASS | 9.57/10 (4GPU), 9.47/10 (8GPU) |
| Math / logic | PASS | 10/10 MT-Bench math category |
| Latency for interactive use | MARGINAL | 1.3-1.6s TTFT — fine for chat, too slow for inline |
| Batch throughput | PASS | 8,407 tok/s peak (8GPU), 6,615 tok/s (4GPU) |
Eleven out of twelve: PASS. One MARGINAL. Zero FAIL. We have never scored a model this cleanly.
What "100% Coding Accuracy" Actually Means
Let us be precise about this, because the number sounds too good to be true.
Our coding evaluation is not HumanEval. HumanEval tests whether a model can write def two_sum(nums, target) — toy problems that any model released after 2024 can pass. Our suite tests 8 categories that map to what engineers actually do:
- Completion — finish partially written functions with correct types, edge cases, and style consistency
- Algorithm — implement non-trivial data structures and algorithms from a specification
- Bugfix — identify and correct bugs in existing code, including off-by-one errors, race conditions, and logic inversions
- Multi-language — produce idiomatic code across Python, JavaScript/TypeScript, Go, Rust, Java, and C++
- Explanation — read complex code and produce accurate, structured explanations of what it does and why
- SQL — generate correct queries across JOIN types, window functions, CTEs, and subqueries
- System design — reason about architecture decisions, trade-offs, and scaling patterns
- Regex — produce correct regular expressions for non-trivial pattern matching requirements
Qwen3 Coder scored 100% across all eight categories on both the 4-GPU and 8-GPU configurations. That is not a rounding artifact. Every test case passed. The model did not stumble on a single regex, miss a single edge case in a bugfix, or produce a single incorrect SQL join.
For context: Nemotron Ultra 253B scored 100% on coding but failed completely on tool use (0%). MiniMax M2.5 scored well on coding but dropped to 87% on tool use. Qwen3 Coder is the first model we have tested that combines perfect coding with strong tool use (93%) and strong instruction following (90%).
Why TTFT Matters More Than You Think for Code Assistants
The one MARGINAL on our scorecard is time-to-first-token: 1,328ms on 8GPU, 1,608ms on 4GPU. Whether this matters depends entirely on how you deploy the model.
Inline code completion (Copilot-style): Does not work
Inline completion needs to feel instant. GitHub Copilot targets under 200ms TTFT. At 1.3 seconds, the developer has already typed the next three lines. Qwen3 Coder cannot replace Copilot for inline autocomplete. Full stop.
Chat-based code review: Works well
When an engineer opens a chat panel, asks "explain this function" or "find bugs in this diff," a 1.3-second pause before the response starts streaming is completely acceptable. Humans expect a brief thinking delay for complex questions. This is Qwen3 Coder's sweet spot.
Batch processing (PR reviews, migrations): Irrelevant
For automated PR review pipelines, code migration scripts, or batch documentation generation, TTFT is irrelevant. What matters is throughput: how many tokens per second can you push through the system. At 8,407 tok/s (8GPU) or 6,615 tok/s (4GPU), Qwen3 Coder can review hundreds of pull requests per hour.
Our recommendation: deploy Qwen3 Coder for chat-based code assistance and batch automation. Keep a smaller, faster model (or Copilot) for inline completion. This is not a compromise — it is how most production systems are already architected.
The Tool Use Question
93% tool use accuracy (14 out of 15 test cases) puts Qwen3 Coder in a different category from most open-weight models.
Tool use is the capability that separates "chat model" from "agent." It means the model can:
- Parse function signatures and call them with correct arguments
- Chain multiple tool calls to accomplish multi-step tasks
- Handle conditional logic (if the first call returns X, then call Y)
- Work with structured API responses
For comparison:
| Model | Tool Use | Implication |
|---|---|---|
| Nemotron Ultra 253B | 0% | Cannot be used for agentic workflows |
| MiniMax M2.5 229B | 87% | Usable but misses edge cases |
| Qwen3 Coder | 93% | Production-viable for agentic coding |
This matters because the future of code assistants is agentic. A model that can only generate code is useful. A model that can generate code and run tests, read error logs, search documentation, and iterate on its own output — that is an engineering force multiplier. Qwen3 Coder has the tool use capability to support that workflow.
4 GPUs or 8? The Practical Scaling Question
We tested both configurations specifically to answer this deployment question. Here is the data:
| Metric | 4x H100 SXM | 8x H100 SXM | Scaling |
|---|---|---|---|
| InferenceMax (conc=128) | 6,615 tok/s | 8,407 tok/s | +27% |
| Best throughput (conc=32) | 3,509 tok/s | 4,463 tok/s | +27% |
| TTFT (conc=1) | 1,608 ms | 1,328 ms | -17% |
| MT-Bench overall | 9.57/10 | 9.47/10 | -1% |
| IFBench | 85% | 90% | +6% |
| Coding accuracy | 100% | 100% | Identical |
| GPU scaling efficiency | — | — | ~64% |
Doubling the GPUs gives you 27% more throughput at roughly 64% scaling efficiency. The quality numbers are essentially identical — 4GPU actually scores marginally higher on MT-Bench (9.57 vs 9.47), though that difference is within noise.
Our recommendation for most teams: start with 4 GPUs.
4x H100 gives you 6,615 tok/s peak throughput, 100% coding accuracy, and the same quality ceiling. Go to 8 GPUs only if you are serving more than roughly 100 concurrent engineering users and need the extra headroom, or if you want the slightly better TTFT (1.3s vs 1.6s).
The Economics of Replacing Copilot
This is the calculation that every engineering leader will eventually run. Let us do it with real numbers.
GitHub Copilot cost
- Individual: $19/user/month
- Business: $39/user/month
- Enterprise: custom pricing, typically $40-50/user/month
For a 50-person engineering team on Copilot Business: $23,400/year.
Self-hosted Qwen3 Coder cost (4x H100 SXM)
- H100 SXM cloud cost: ~$2.49/GPU/hour (reserved pricing on major clouds)
- 4 GPUs x 730 hours/month = $7,271/month = $87,252/year
- Add ~10% for networking, storage, ops overhead: ~$96,000/year
The break-even math
At $39/user/month (Copilot Business), the self-hosted option breaks even at approximately 225 developers. Below that headcount, Copilot is cheaper per seat. Above it, self-hosted wins — and the gap widens fast.
At 500 engineers: Copilot costs $234,000/year. Self-hosted Qwen3 Coder costs $96,000/year. That is a $138,000 annual savings.
But cost is not the only variable. Self-hosting gives you:
- Data privacy — your code never leaves your infrastructure. For regulated industries (finance, healthcare, defense), this is not optional, it is a requirement.
- Customization — fine-tune on your codebase, your coding standards, your internal frameworks
- No vendor lock-in — swap models without changing your tooling
- No rate limits — Copilot throttles heavy users. Self-hosted does not.
- Audit trail — full logging of every query and response for compliance
For organizations under 225 engineers without strict data privacy requirements, Copilot remains the pragmatic choice. For larger teams or regulated environments, Qwen3 Coder on 4x H100 is the most cost-effective self-hosted option we have benchmarked.
Use our inference cost calculator to run these numbers for your specific cloud provider and team size.
What Qwen3 Coder Cannot Do
Every evaluation that only talks about strengths is a marketing document. Here is what does not work.
Inline code completion
We covered this above, but it bears repeating: 1.3-1.6 second TTFT disqualifies Qwen3 Coder from Copilot-style inline autocomplete. You need sub-200ms for that use case. A smaller model like Qwen2.5-Coder-7B or a speculative decoding setup would be needed for the inline path.
No vision capabilities
Qwen3 Coder cannot analyze screenshots, read diagrams, interpret UI mockups, or process whiteboard photos. If your workflow involves "here is a screenshot of the bug" or "implement this Figma design," you need a multimodal model.
No web browsing
The model cannot look up documentation, check Stack Overflow, or verify API references in real time. Its knowledge is frozen at training time. For up-to-date library docs, you need a RAG pipeline or web-search-augmented setup on top of the model.
MT-Bench self-judging caveat
As with all our MT-Bench evaluations, scores are self-judged (model-as-judge). This tends to inflate scores by 0.3-0.5 points compared to human evaluation. The 9.57 is likely closer to 9.1-9.3 on a human-judged scale. Still excellent, but we disclose this consistently.
How It Compares to What Engineering Teams Actually Use
The models below are not theoretical alternatives. They are what engineering teams are actually deploying or paying for right now.
vs Claude Sonnet 4 (API)
Claude excels at complex multi-file reasoning and long-context code understanding. For difficult architectural questions and large refactors, Claude is likely still superior. But Claude is an API — your code goes to Anthropic's servers, you pay per token, and you are subject to rate limits. Qwen3 Coder gives you comparable coding accuracy (100% vs Claude's strong but not independently benchmarked coding), complete data privacy, and 100x lower per-token cost at scale.
vs GPT-4o (API)
Comparable coding quality. GPT-4o has better vision capabilities (which Qwen3 Coder lacks entirely) and stronger web-browsing integration via ChatGPT. Qwen3 Coder wins on self-hosting advantage, no rate limits, and cost at scale. For pure code generation tasks, the quality gap is negligible.
vs Codestral 22B (open-weight)
Codestral is significantly smaller and faster for inline completion use cases. Qwen3 Coder is a much larger model with substantially better quality on complex reasoning, system design, and multi-step coding tasks. These are not competitors — they serve different layers of the stack. Run Codestral for inline completion, Qwen3 Coder for everything else.
vs DeepSeek Coder V2 (open-weight)
Similar quality tier on raw coding benchmarks. Qwen3 Coder's advantage is tool use (93% vs DeepSeek's weaker tool calling) and instruction following (90% IFBench). For agentic coding workflows — where the model needs to call APIs, run tests, and iterate — Qwen3 Coder is the stronger choice.
vs GitHub Copilot
Entirely different deployment model. Copilot is a managed service optimized for inline completion. Qwen3 Coder is a self-hosted model optimized for chat, review, and batch processing. See the economics section above for the cost comparison. For most teams, the answer is "use both" — Copilot for inline, Qwen3 Coder for everything else.
The Shortest Path to Production
If you have decided to deploy, here is how to get Qwen3 Coder running on your infrastructure.
vLLM on 4x H100 (recommended)
docker run --gpus '"device=0,1,2,3"' \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-p 8000:8000 \
--ipc=host \
vllm/vllm-openai:latest \
--model Qwen/Qwen3-Coder \
--tensor-parallel-size 4 \
--max-model-len 32768 \
--enable-auto-tool-choice \
--tool-call-parser hermes
This gives you an OpenAI-compatible API at http://localhost:8000. Any tool that speaks the OpenAI chat completions format can connect to it.
VS Code integration concept
Point the Continue extension (or similar) at your vLLM endpoint. Configure it for chat-based assistance, not inline completion. Your engineers get a code review and explanation assistant that runs entirely on your hardware.
CI/CD PR review pipeline concept
Wire a GitHub Action or GitLab CI job that sends PR diffs to your vLLM endpoint, collects the model's review comments, and posts them as PR review comments. At 6,615 tok/s, the model can review a 1,000-line diff in under 10 seconds.
For full deployment scripts, infrastructure-as-code templates, and production hardening guides, reach out via our support page.
The Verdict
We have benchmarked dozens of models through this pipeline. Most of them are good at some things and mediocre at others. Qwen3 Coder is the first model that passed every coding capability we test and backed it up with strong general reasoning, tool use, and instruction following.
The recommendation depends on your team:
- Fewer than 50 engineers, no data privacy requirements: GitHub Copilot is still the most practical choice. Lower total cost, zero ops burden, excellent inline completion.
- 50-225 engineers, data privacy matters: Self-host Qwen3 Coder on 4x H100 for chat-based code assistance and batch automation. Keep Copilot for inline completion. The combined cost is lower than Copilot Business alone once you factor in the privacy and customization value.
- 225+ engineers: Self-hosted Qwen3 Coder is cheaper than Copilot in absolute terms. At this scale, you should be running your own inference infrastructure regardless. Qwen3 Coder on 4x H100 is the best model we have tested for that deployment.
The one non-negotiable caveat: if you need inline autocomplete at sub-200ms latency, Qwen3 Coder is not the right model for that specific use case. Pair it with a smaller, faster model for the inline path.
Qwen3 Coder does not do everything. But what it does, it does right. Every time. Across every test we ran. That consistency is what makes it deployable.
Test Methodology
All benchmarks ran on identical hardware: NVIDIA H100 SXM GPUs with NVLink interconnect, served via vLLM with tensor parallelism. Configurations tested: 4x H100 (TP=4) and 8x H100 (TP=8). Throughput measured at ISL/OSL combinations of 128/512, 128/1024, 512/512, and 512/1024 across concurrency levels 1, 8, 32, and 128. Quality benchmarks: MT-Bench (8 categories, self-judged), InferenceBench Coding Suite (8 categories), IFBench (instruction following), Tool Use (15 scenarios), Long Context (29 tests). Full methodology and raw data available on InferenceBench.
More articles
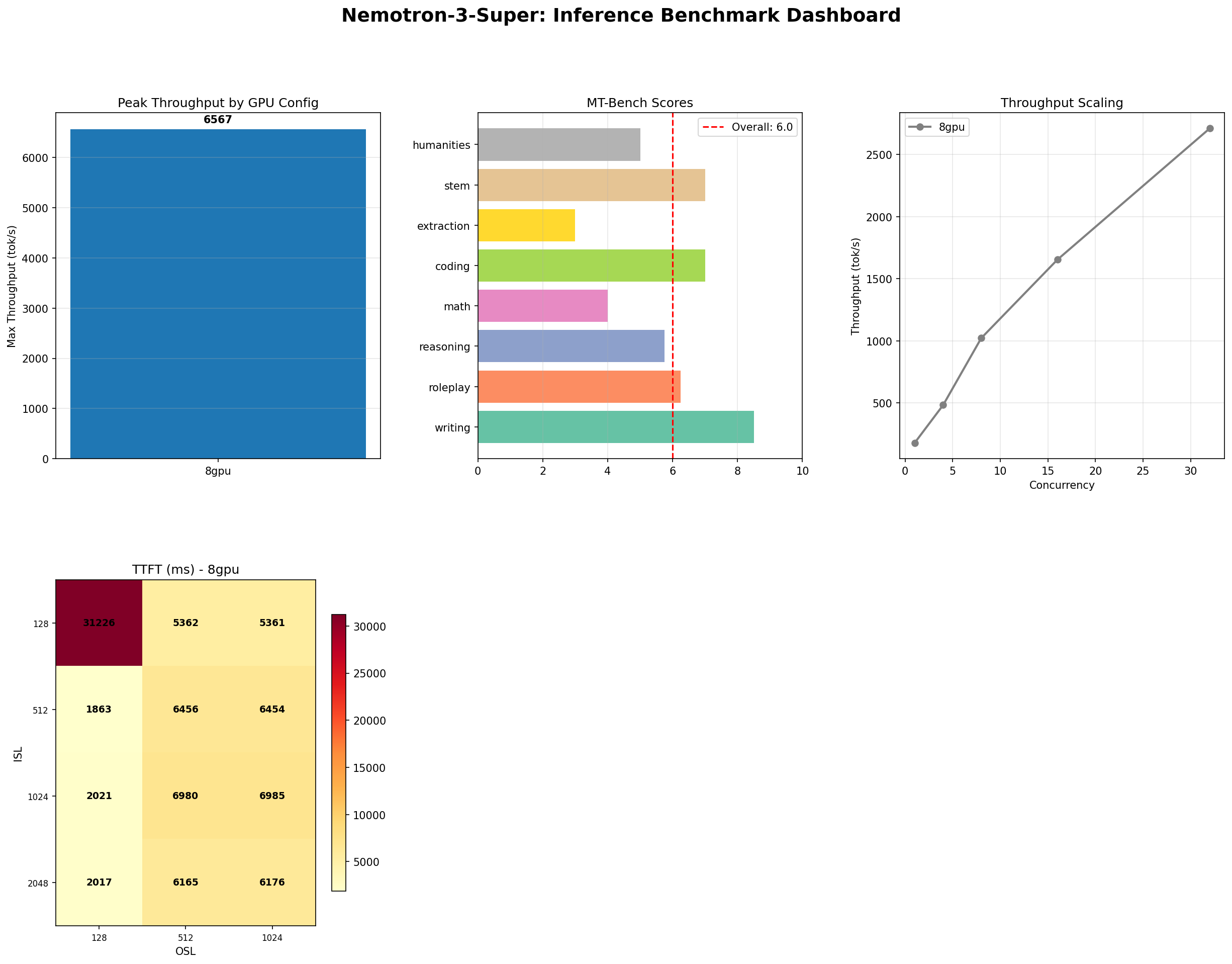
Nemotron Super 120B vs Ultra 253B: NVIDIA's Best Open-Weight Models Benchmarked
Nemotron Ultra FP8 scores 9.47 MT-Bench, beating its own BF16 at 9.2. Super hits 6,567 tok/s. Both fail tool use and vision at 0%. Full SWOT analysis.
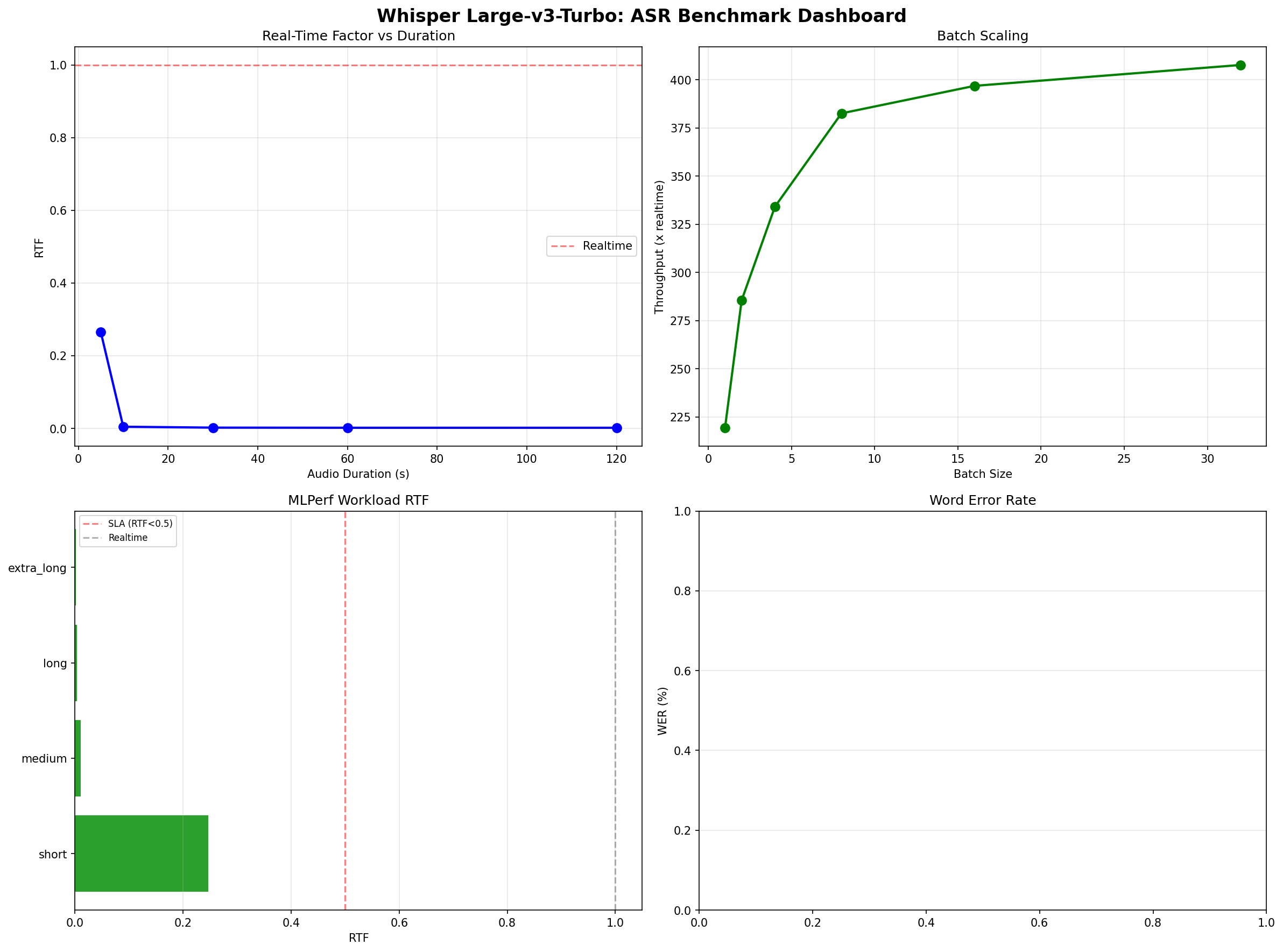
Whisper v3-Turbo on H100: 597x Realtime ASR Benchmark
Whisper Large-v3-Turbo benchmarked on H100: 597x realtime transcription, 404x at batch=32, $0.00007/min self-hosted, but 44% hallucination on silence.
The GPU Memory Wall: Forecasting AI Demand to 2028
GPU memory is the defining bottleneck of AI infrastructure. We analyze the demand curve from HBM3e through HBM4E, forecast requirements to 2028, and outline strategies to stay ahead.