InferenceBench Blog
Insights, benchmarks, and deep dives into GPU inference economics, model performance, and AI infrastructure.
12 posts
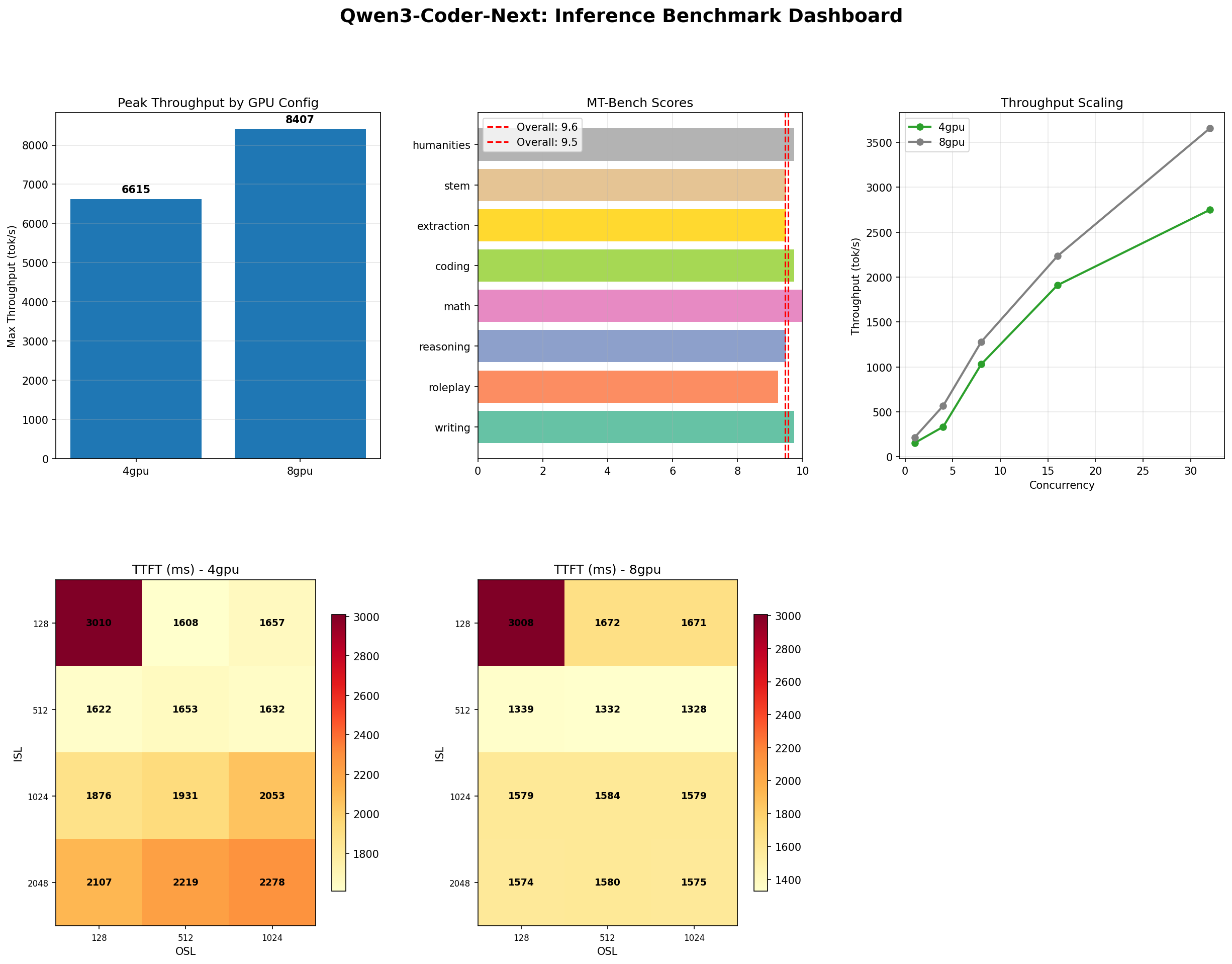
Qwen3 Coder: The Model That Does Everything Right
100% coding accuracy across 8 categories, 9.57 MT-Bench, 93% tool use, 8,407 tok/s. Our deployment evaluation for engineering teams considering self-hosted code AI.
Stay updated with the latest benchmarks and insights. Follow us on LinkedIn
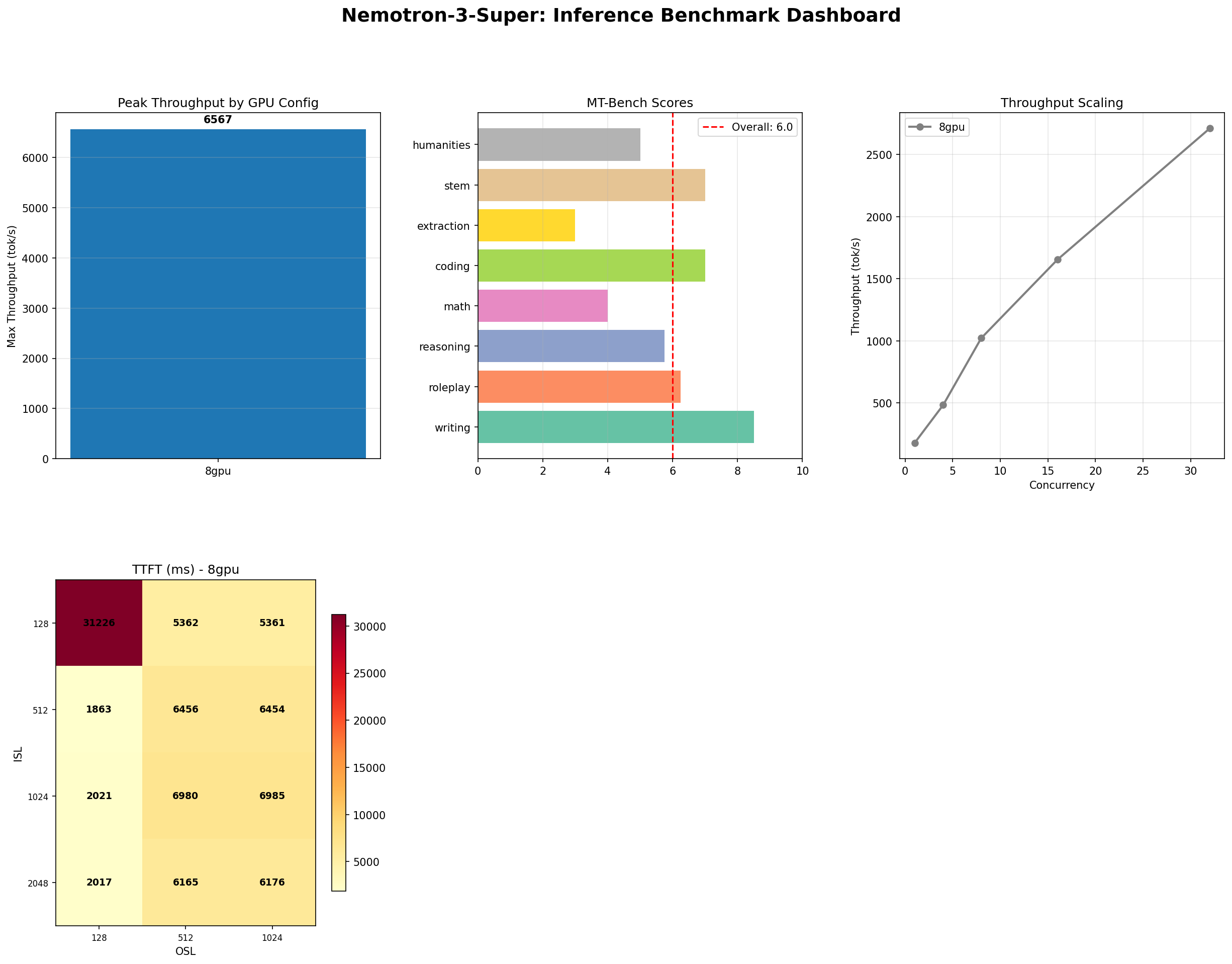
Nemotron Super 120B vs Ultra 253B: NVIDIA's Best Open-Weight Models Benchmarked
Nemotron Ultra FP8 scores 9.47 MT-Bench, beating its own BF16 at 9.2. Super hits 6,567 tok/s. Both fail tool use and vision at 0%. Full SWOT analysis.
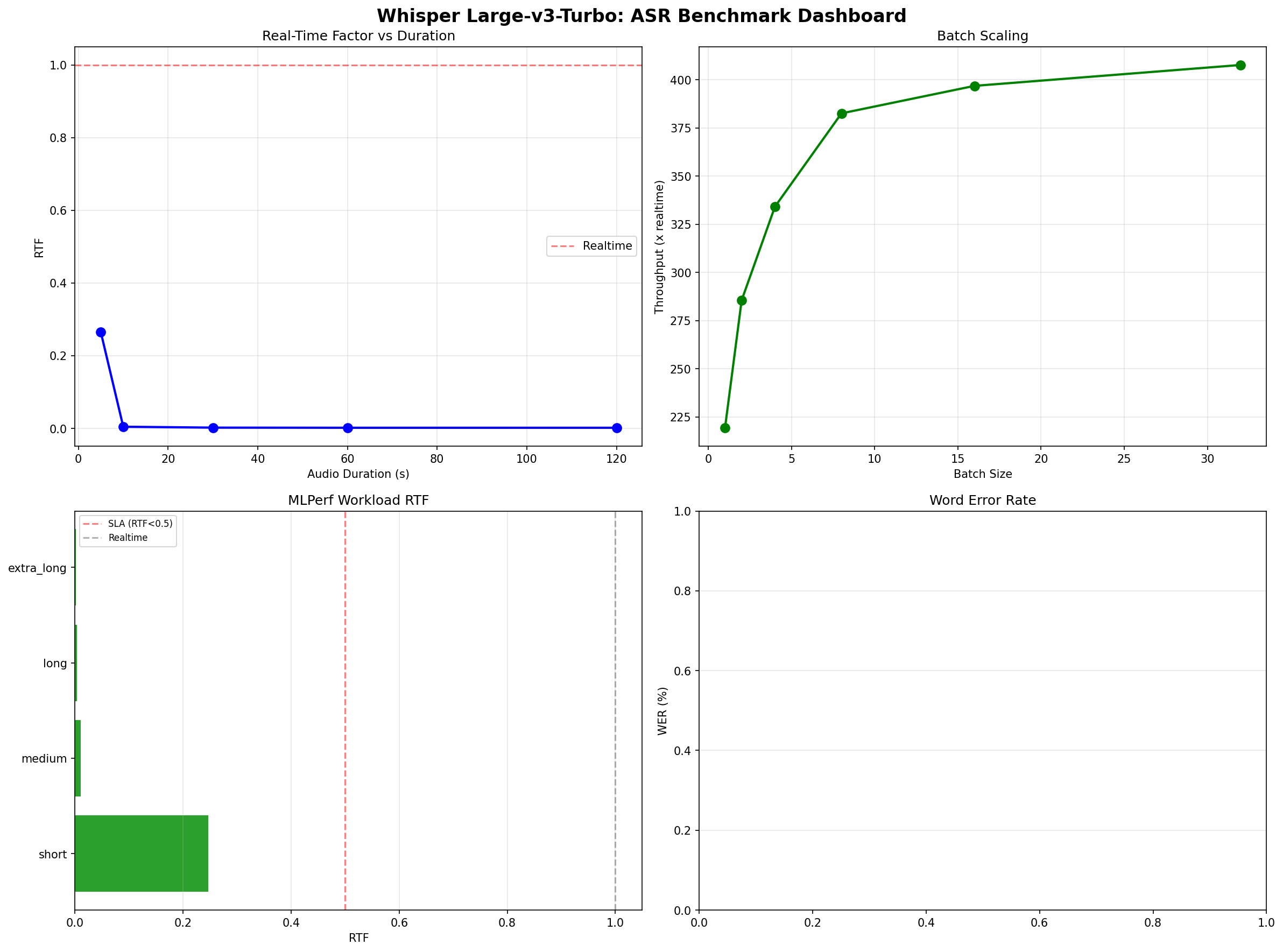
Whisper v3-Turbo on H100: 597x Realtime ASR Benchmark
Whisper Large-v3-Turbo benchmarked on H100: 597x realtime transcription, 404x at batch=32, $0.00007/min self-hosted, but 44% hallucination on silence.
The GPU Memory Wall: Forecasting AI Demand to 2028
GPU memory is the defining bottleneck of AI infrastructure. We analyze the demand curve from HBM3e through HBM4E, forecast requirements to 2028, and outline strategies to stay ahead.
NVIDIA Rubin and Vera: The Next GPU Revolution for AI Infrastructure
NVIDIA Rubin brings HBM4, NVLink 6, and 2x Blackwell performance. Paired with the Vera ARM CPU, it reshapes AI inference economics for every cloud and datacenter operator.
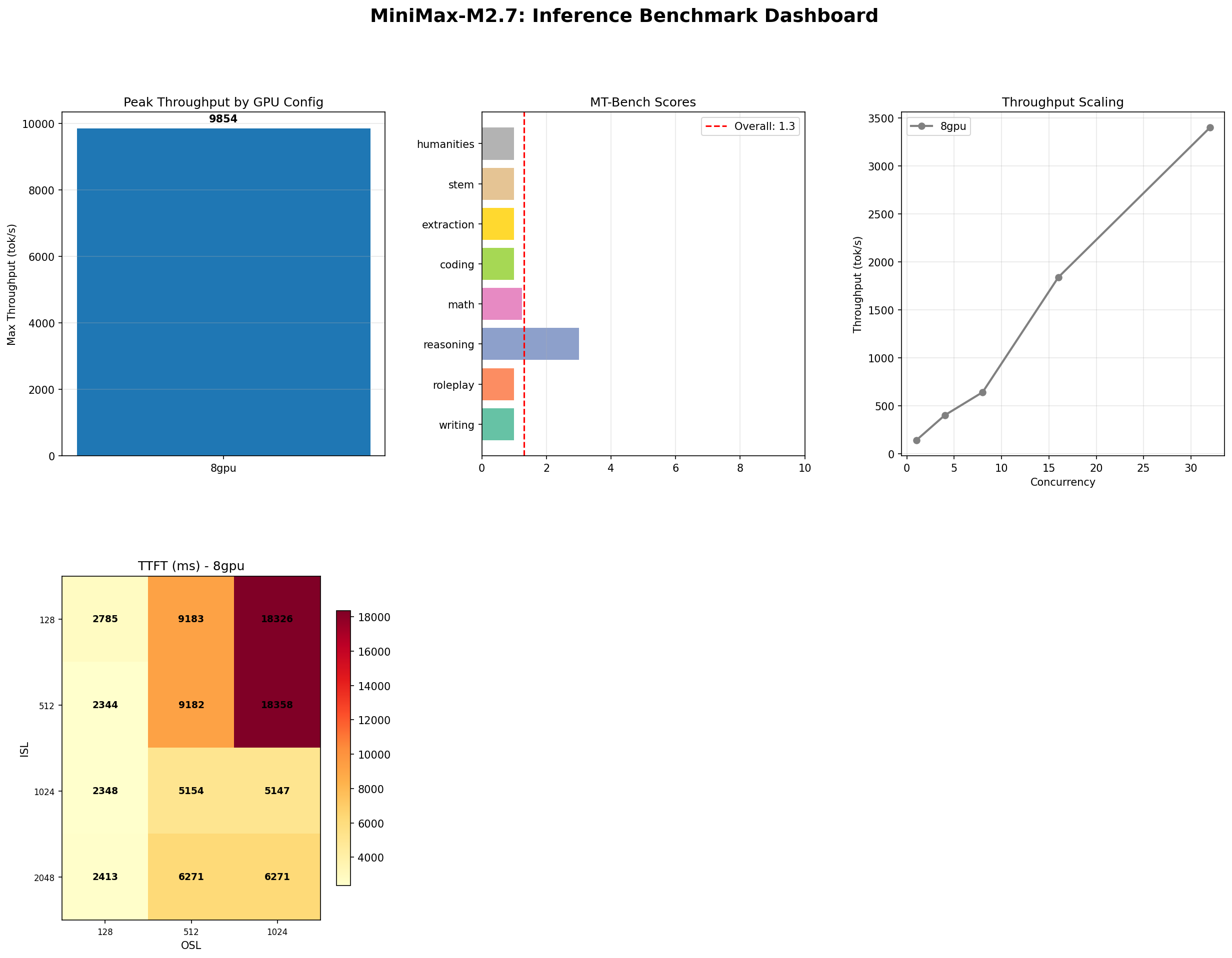
MiniMax M2.7: The Bigger MoE Paradox
MiniMax M2.7 456B MoE on 8x H100: 9,854 tok/s peak, 93% tool use, but MT-Bench dropped to 1.30. Bigger is not always better.
MiniMax M2.5 vs M2.7: Does Doubling MoE Params Help?
Head-to-head benchmark of MiniMax M2.5 (229B) vs M2.7 (456B) on 8x H100: 11% throughput gain but 17% MT-Bench drop. More MoE params does not mean better.
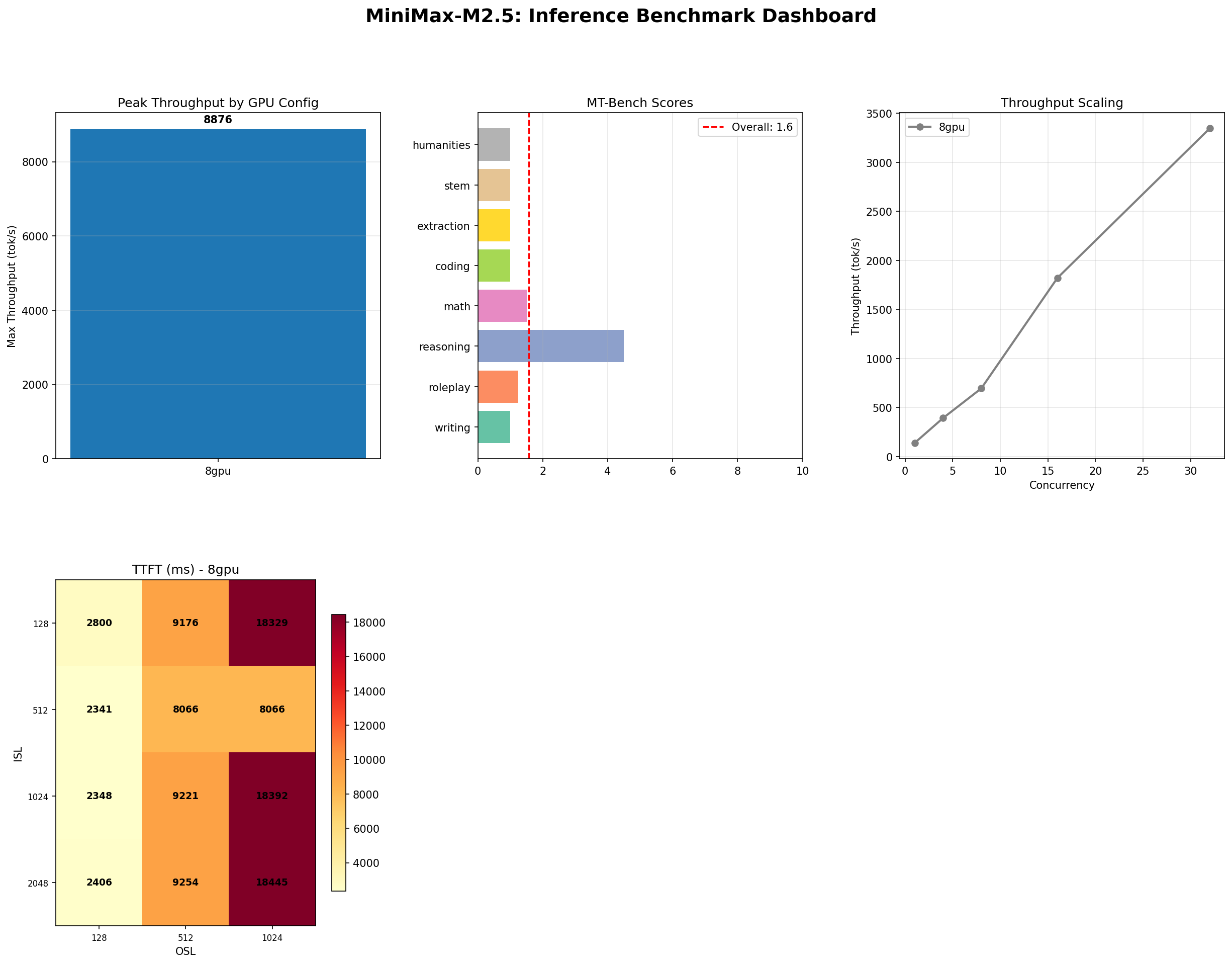
MiniMax M2.5: A 229B MoE Model That Defies Easy Judgment
MiniMax M2.5 229B MoE benchmarked on 8x H100: 8,876 tok/s peak, 100% needle-in-haystack, 87% tool use, but 1.57/10 MT-Bench. The full contradictory picture.
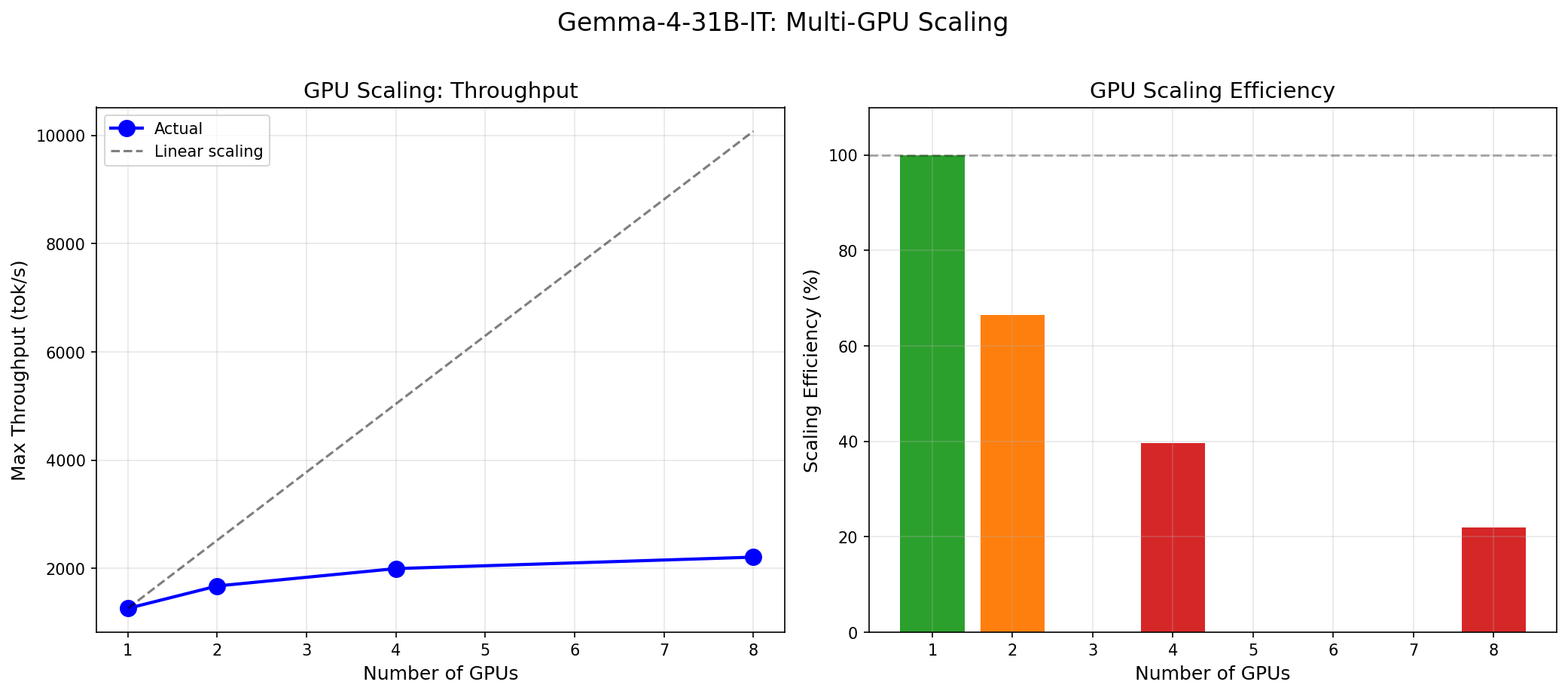
Gemma 4 vs the MoE Field: When a 31B Dense Model Wins and When It Doesn't
Gemma 4 31B scores 9.73/10 MT-Bench from 31B dense params. We compare it against Mixtral 8x22B and DeepSeek V3 on cost, latency, and quality tradeoffs.

FLUX.2-klein-4B on H100: Image Generation Benchmark
FLUX.2-klein-4B benchmarked on H100: 0.19s per image at 512x512, CLIP 0.335, 97% multi-GPU efficiency, and $0.0004/image self-hosted. Full results inside.
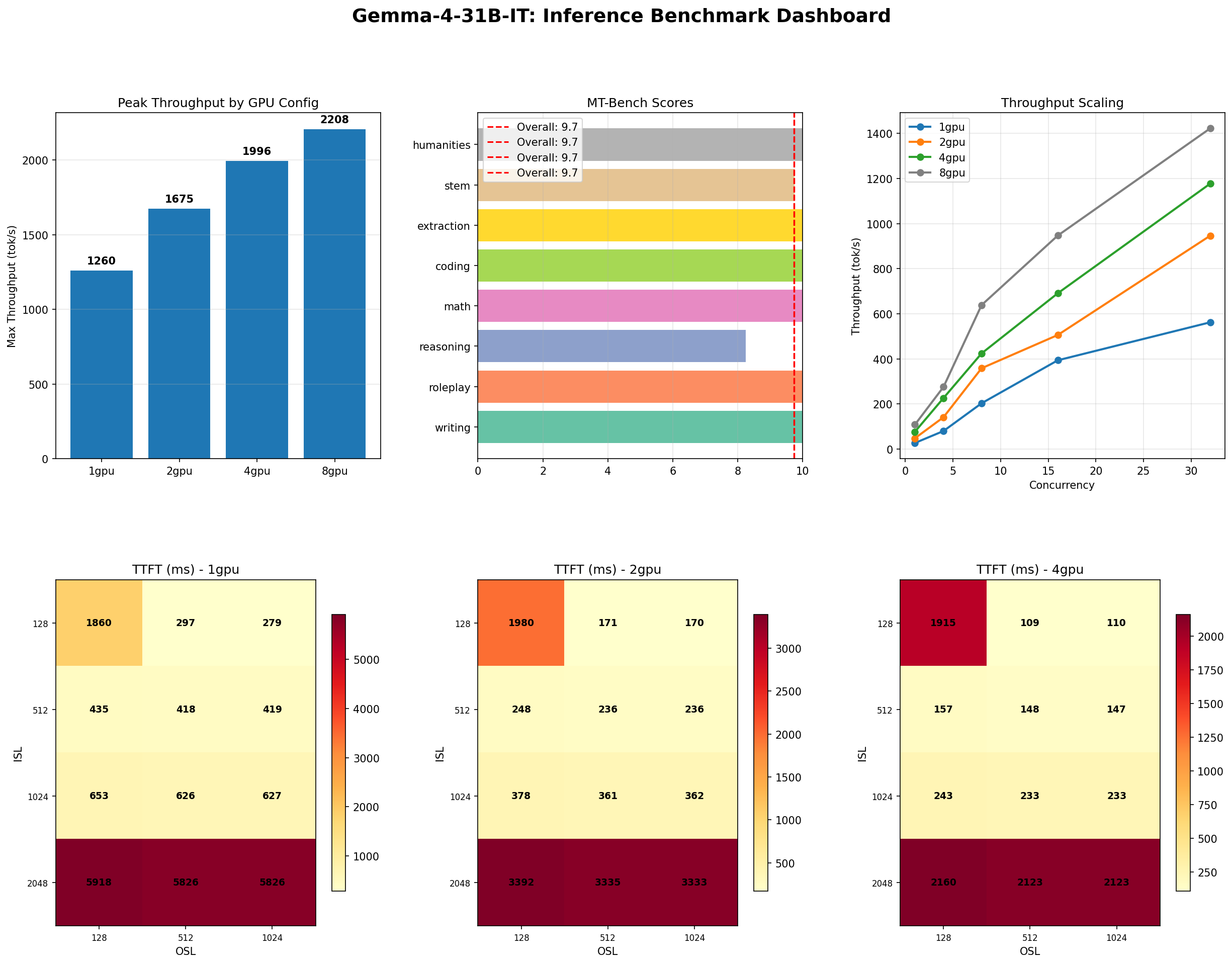
Gemma 4 31B on H100: The Complete Inference Benchmark
Gemma 4 31B benchmarked across 1-8 H100 GPUs: 240 throughput sweeps, stress tests, MT-Bench 9.73/10, and Pareto analysis. Peak: 3,050 tok/s on 8 GPUs.
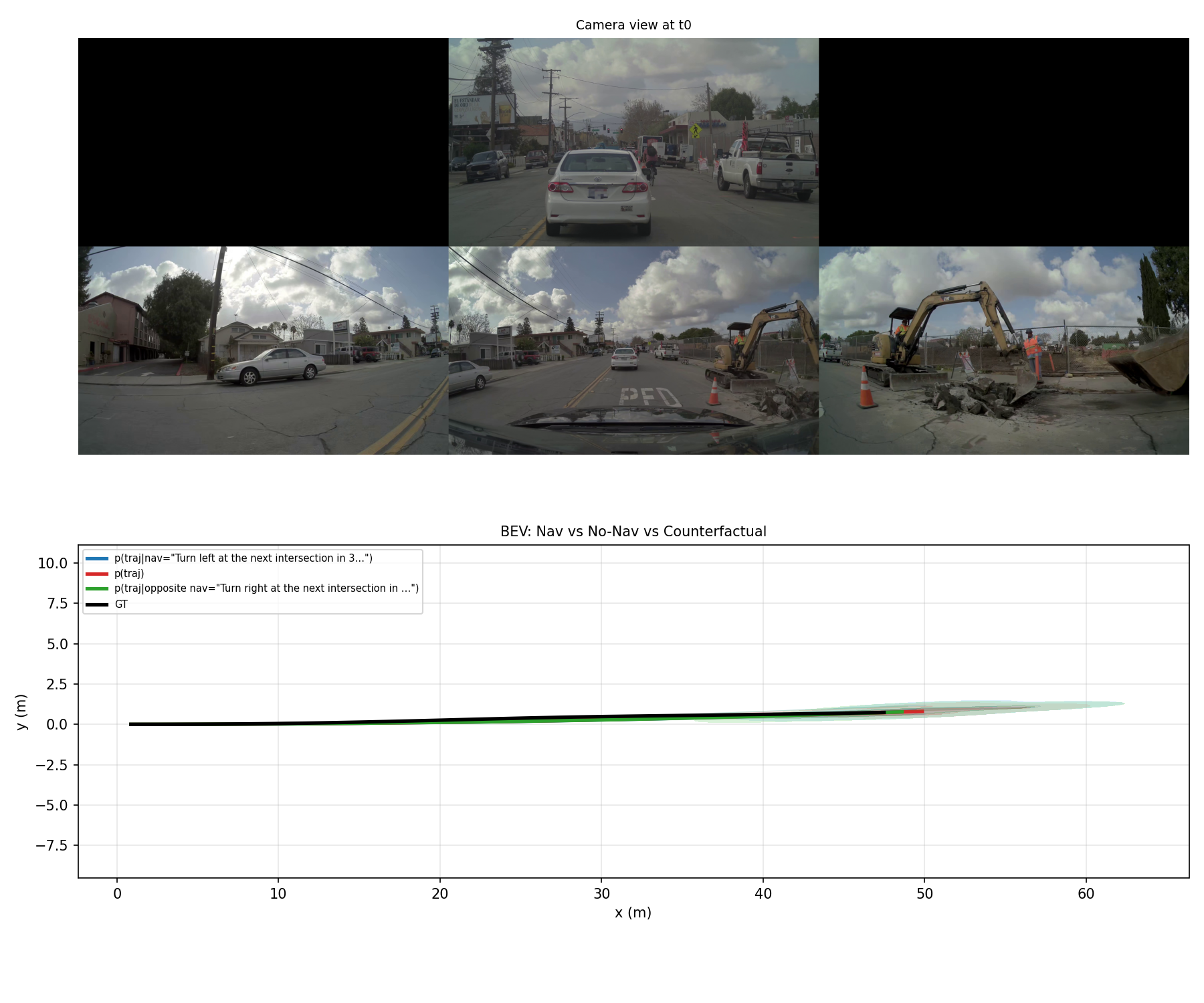
NVIDIA Alpamayo 1.5-10B on H100: Autonomous Driving Inference Benchmark
We benchmarked NVIDIA Alpamayo 1.5-10B across 5 inference modes on a single H100 GPU: CoC reasoning, VQA, nav-conditioned prediction, counterfactuals, and uncertainty.