NVIDIA Rubin and Vera: The Next GPU Revolution for AI Infrastructure
A deep technical analysis of NVIDIA's post-Blackwell GPU architecture, the Vera CPU, and what they mean for inference economics, neoclouds, and datacenter operators worldwide.
Introduction: The AI Infrastructure Arms Race
Every generation of NVIDIA GPUs has changed the rules. Hopper made trillion-parameter training feasible. Blackwell made large-scale inference economically viable. Now, with Rubin, NVIDIA is making a bet that the next frontier is not simply more compute — it is fundamentally better memory, interconnect, and system-level integration at a scale that rewrites the economics of every AI workload.
The announcement of the NVIDIA Rubin architecture and its companion Vera CPU at GTC 2025 was not just a product launch. It was a declaration that the GPU roadmap is now on a one-year cadence, that the CPU-GPU boundary is dissolving, and that the datacenter itself is the new unit of compute. For organizations running large language model inference — from hyperscalers to neocloud operators to enterprises running private deployments — Rubin represents the single largest inflection point since the H100.
This post is a technical deep-dive into what Rubin and Vera are, what they change, and what they mean for anyone who cares about the cost, speed, and scale of AI inference. We will cover architecture, memory systems, interconnect, deployment models, datacenter requirements, economics projections, and a realistic timeline. Where we speculate, we will say so clearly. Where the data is public, we will cite it.
If you are sizing GPU infrastructure for AI workloads today, you can use the InferenceBench calculator to model your current costs. This post is about what those costs look like in eighteen months.
What Is Rubin? Architecture Deep-Dive
Rubin is NVIDIA's next-generation GPU architecture, succeeding Blackwell in the company's accelerated computing roadmap. Jensen Huang confirmed the Rubin architecture during his GTC 2025 keynote in March 2025, positioning it as a 2026 product with silicon expected to ship in the second half of that year. The naming follows NVIDIA's tradition of honoring scientists — Vera Rubin was the American astronomer whose work provided foundational evidence for dark matter.
The Memory Revolution: HBM4
The most consequential change in Rubin is the transition from HBM3e to HBM4. This is not an incremental bump. HBM4 represents a generational leap in memory bandwidth and capacity that directly impacts every memory-bound AI workload — which, at inference time, is nearly all of them.
| Specification | Hopper H100 | Blackwell B200 | Rubin (Expected) |
|---|---|---|---|
| Memory Type | HBM3 | HBM3e | HBM4 |
| Memory Capacity | 80 GB | 192 GB | Up to 288 GB (expected) |
| Memory Bandwidth | 3.35 TB/s | 8 TB/s | ~12-16 TB/s (projected) |
| Memory Interface | 5120-bit | 8192-bit | Wide I/O (expected wider) |
For LLM inference, memory bandwidth is the primary bottleneck during the autoregressive decode phase. Each token generated requires reading the full KV-cache and model weights from HBM. A model like Llama 3.1-405B in FP16 consumes approximately 810 GB of weight memory alone. On today's H100 cluster, you need a minimum of 11 GPUs just for the weights. With Rubin's expected 288 GB HBM4 capacity, that drops to 3 GPUs — and the bandwidth increase means each of those GPUs can feed its compute units faster.
The practical impact: models that currently require 8-GPU configurations on Blackwell may fit into 2-4 GPU configurations on Rubin, with higher tokens-per-second throughput. This is not speculation about compute improvements — it is arithmetic about memory capacity and bandwidth. You can model current multi-GPU configurations using the InferenceBench Workload Matcher.
Compute Density and Process Node
Rubin is expected to be manufactured on TSMC's next-generation process node (likely 3nm or an advanced variant), continuing the trend of each GPU generation moving to a denser process. While NVIDIA has not published detailed SM (Streaming Multiprocessor) counts for Rubin, the company has indicated approximately 2x the AI compute performance of Blackwell across both training and inference workloads.
This 2x figure should be interpreted carefully. NVIDIA's generational performance claims typically combine improvements in:
- Raw FP8/FP4 throughput — more tensor cores, higher clock speeds
- Memory bandwidth — the HBM4 advantage described above
- Sparsity exploitation — structured sparsity support has improved each generation
- Software stack — TensorRT, CUDA, and inference runtime improvements that ship alongside the hardware
For inference specifically, the memory bandwidth improvement alone could account for 50-70% of the performance gain on decode-bound workloads. The remaining improvement comes from higher compute density and better utilization of that compute through architectural refinements.
NVLink 6: The Fabric Upgrade
Rubin introduces NVLink 6, the next generation of NVIDIA's proprietary GPU-to-GPU interconnect. NVLink has been the critical technology that enables multi-GPU inference and training at scale, and each generation has roughly doubled bandwidth while improving the programming model.
| NVLink Generation | GPU Architecture | Bandwidth (bidirectional) |
|---|---|---|
| NVLink 4 | Hopper H100 | 900 GB/s |
| NVLink 5 | Blackwell B200 | 1.8 TB/s |
| NVLink 6 | Rubin | ~3.6 TB/s (expected) |
For tensor-parallel inference, NVLink bandwidth directly determines the overhead of splitting a model across GPUs. With NVLink 6, the communication overhead for an 8-way tensor-parallel configuration on Rubin should be roughly half that of the same configuration on Blackwell. This means tensor parallelism remains efficient even at higher parallelism degrees, enabling single-node inference for models that previously required multi-node setups.
NVIDIA has also indicated that NVLink 6 will support larger NVLink domains — the number of GPUs that can communicate via NVLink within a single coherent memory space. Blackwell's GB200 NVL72 configuration put 72 GPUs in a single NVLink domain. Rubin is expected to push this further, potentially to 144 or more GPUs in a single domain, which would allow trillion-parameter models to be served from a single NVLink-connected rack with no InfiniBand overhead.
PCIe Gen6 Support
Rubin is expected to support PCIe Gen6, doubling the host-device bandwidth from PCIe Gen5's 64 GB/s to approximately 128 GB/s per direction. While NVLink handles GPU-to-GPU communication, PCIe remains important for CPU-GPU data transfer, storage I/O, and network interface connectivity. For inference workloads that involve significant prompt preprocessing or that shuffle data between host memory and GPU memory, this is a meaningful improvement.
Vera: The CPU That Completes the Picture
Vera is NVIDIA's next-generation ARM-based CPU, designed as the successor to the Grace CPU that debuted alongside Hopper. Where Grace was NVIDIA's first serious CPU — proving that the company could build a competitive server processor — Vera is the refinement that makes the CPU-GPU integration seamless enough to change system architecture.
Why CPU-GPU Coherence Matters for LLM Inference
In a traditional server, the CPU and GPU are connected via PCIe. Data must be explicitly copied between CPU memory (DRAM) and GPU memory (HBM). This copy overhead is small for training workloads where large batches amortize the cost, but it is significant for latency-sensitive inference, especially for:
- KV-cache offloading — moving less-frequently-accessed KV-cache pages to CPU memory to serve longer contexts
- Speculative decoding — where a small draft model on the CPU proposes tokens verified by the large model on the GPU
- Preprocessing pipelines — tokenization, embedding lookup, and prompt assembly that happen on the CPU before GPU inference begins
- Mixture-of-experts routing — where expert selection logic may involve CPU-side decisions
Grace introduced cache-coherent NVLink between the CPU and GPU — called NVLink-C2C (chip-to-chip). This meant the CPU and GPU could share a unified memory space without explicit copies. Vera deepens this integration. It is designed from the ground up for the NVLink domain, meaning:
- The CPU's memory appears as part of the GPU's address space (and vice versa)
- Cache coherence is maintained across the CPU-GPU boundary at hardware speed
- The CPU can directly access GPU HBM4 memory, and the GPU can directly access CPU DDR/LPDDR memory, without software-managed DMA
For inference, this means KV-cache paging between CPU and GPU memory becomes a hardware-speed operation rather than a software-managed copy. A system running vLLM or TensorRT-LLM with PagedAttention can extend its effective context window by using CPU memory as a transparent overflow tier. With Grace, this was possible but added latency. With Vera, the latency penalty is expected to shrink dramatically.
Grace vs. Vera: What Changes
| Feature | Grace (Hopper/Blackwell era) | Vera (Rubin era, expected) |
|---|---|---|
| Architecture | ARM Neoverse V2 | ARM Neoverse (next-gen, expected V3 or custom) |
| CPU-GPU Link | NVLink-C2C (900 GB/s) | NVLink-C2C Gen2 (expected higher bandwidth) |
| Memory | LPDDR5X (up to 480 GB) | DDR5 or LPDDR5X (expected larger capacity) |
| Cores | 72 ARM cores | Expected higher core count |
| Integration | Paired with Hopper/Blackwell | Designed specifically for Rubin NVLink domain |
| Target | General AI server CPU | NVLink-native AI server CPU |
The critical difference is not in raw CPU performance — Vera will be a faster ARM CPU, but the gap between Grace and Vera on pure CPU benchmarks is less important than the system-level integration. Vera is designed to be a first-class participant in the NVLink domain, not a host processor that happens to have a fast link to the GPUs. This distinction matters for software frameworks that can exploit unified memory, and NVIDIA's inference stack (TensorRT-LLM, Triton Inference Server) will be optimized to take advantage of it.
Rubin Variants: Rubin, Rubin Ultra, and System Configurations
Following the pattern established with Blackwell (B200, B200A, GB200, GB200 NVL72), NVIDIA has outlined multiple Rubin SKUs targeting different market segments.
Rubin (Standard)
The base Rubin GPU is expected to be the volume product, analogous to the B200. It will feature:
- Up to 288 GB HBM4
- NVLink 6 connectivity
- PCIe Gen6 host interface
- Expected TDP around 1000W
- Availability: H2 2026
This is the GPU that neocloud operators and enterprise buyers will deploy in the highest volumes. It targets the sweet spot of inference density — enough memory to serve 70B-parameter models on a single GPU, enough compute to do so at production throughput.
Rubin Ultra
Rubin Ultra is the hyperscale variant, analogous to the B200 Ultra or the "full die" products NVIDIA releases after the initial launch. Expected specs:
- Potentially dual-die or MCM (multi-chip module) design
- Higher HBM4 capacity (possibly 384 GB or more)
- Higher compute throughput
- Expected availability: 2027
Rubin Ultra targets hyperscale training clusters and the largest inference deployments — think frontier model training at OpenAI, Google DeepMind, or Anthropic scale, and serving the largest MoE models (Mixtral-class and beyond) with maximum throughput.
DGX Rubin
NVIDIA announced the DGX Rubin system at GTC 2025. Following the DGX pattern, this will be a turnkey server containing multiple Rubin GPUs with Vera CPUs, NVLink 6 interconnect, and integrated networking. The DGX GB200 contained 36 Grace-Blackwell Superchips in a liquid-cooled rack; DGX Rubin is expected to push density further.
Jensen Huang described DGX Rubin as targeting the "AI factory" use case — organizations that want to deploy inference and training at scale without designing custom server configurations. DGX systems come with NVIDIA's full software stack pre-installed and validated, which significantly reduces time-to-deployment.
SuperPOD and NVLink Domain Configurations
At the datacenter scale, NVIDIA's SuperPOD configurations will use Rubin GPUs connected via NVLink switches to create large NVLink domains. The goal is to make an entire rack — or multiple racks — appear as a single coherent memory space to the software.
For inference, large NVLink domains enable serving models that exceed single-GPU memory without crossing into the slower InfiniBand or Ethernet fabric. A 72-GPU NVLink domain with 288 GB per GPU would provide over 20 TB of coherent GPU memory — enough to serve any current model (including Llama 3.1-405B, GPT-4-class MoE models, and beyond) entirely within the NVLink fabric.
What This Means for Model Inference
The combined improvements in Rubin — more memory, faster memory, faster interconnect, higher compute — do not simply make existing deployments faster. They change which deployment configurations are viable for specific models.
Fewer GPUs Per Model
Consider the current GPU requirements for common models, which you can calculate using the InferenceBench Workload Matcher:
| Model | Size (FP16) | H100 GPUs Needed | B200 GPUs Needed | Rubin GPUs (Projected) |
|---|---|---|---|---|
| Llama 3.1 70B | ~140 GB | 2 | 1 | 1 |
| Llama 3.1 405B | ~810 GB | 11+ | 5 | 3 (projected) |
| Mixtral 8x22B (MoE) | ~280 GB (all experts) | 4 | 2 | 1 (projected) |
| GPT-4 class MoE | ~1.2-1.8 TB (estimated) | 16-24 | 8-10 | 5-7 (projected) |
| Frontier model (2026) | ~3-5 TB (projected) | 40-64 | 16-26 | 11-18 (projected) |
Fewer GPUs per model means lower cost per deployment, lower power consumption per deployment, and more models served per rack. For operators who are capacity-constrained (which, in 2026, is essentially everyone), this is the metric that matters most.
Longer Context Windows Become Practical
Context window length is limited by KV-cache memory. For a 70B model with a 128K context window, the KV-cache alone can consume 40-60 GB of HBM depending on quantization. With 288 GB of HBM4, Rubin can support significantly longer context windows — or serve more concurrent users with moderate context lengths — without KV-cache offloading.
Models with 1M+ token context windows (like Gemini or future Claude versions) currently require aggressive KV-cache compression or multi-GPU distribution. Rubin's combination of larger HBM capacity and coherent CPU memory via Vera makes million-token inference more practical on fewer GPUs, because the Vera CPU's memory can serve as a fast overflow tier for KV-cache pages that are not in the current attention window.
MoE Models on Fewer GPUs
Mixture-of-experts (MoE) architectures like Mixtral, DBRX, and the rumored architectures behind GPT-4 and Gemini have a unique memory profile: the total model is large (because it includes all experts), but the active compute per token is small (because only a subset of experts fire). This means MoE models are extremely memory-capacity-bound.
Rubin's 288 GB HBM4 is transformative for MoE inference. A Mixtral 8x22B model that currently needs 4 H100s could fit on a single Rubin GPU. This eliminates all inter-GPU communication overhead for that model, simplifies deployment, and reduces per-query latency.
Quantized Inference at Scale
With Rubin's expected support for FP4 (4-bit floating point) compute, quantized models become even more attractive. A 405B model quantized to FP4 would require approximately 200 GB — potentially fitting on a single Rubin GPU. Combined with the higher compute throughput at FP4 precision, this could make serving frontier-class models on a single GPU a reality for the first time.
Deployment Methods: How Organizations Will Deploy Rubin
The path from NVIDIA shipping Rubin silicon to organizations running inference workloads on it involves multiple deployment models, each with different timelines and tradeoffs. For a comparison of current cloud GPU providers, see the InferenceBench Provider Comparison.
Hyperscale Cloud (AWS, GCP, Azure)
The hyperscale cloud providers will offer Rubin instances, but historically they are not the first to market with new NVIDIA GPUs. AWS launched H100 instances (p5) in late 2023, roughly a year after H100 started shipping to other customers. A similar cadence would put Rubin cloud instances in early-to-mid 2027.
However, the hyperscalers are under competitive pressure from neoclouds and are working to compress this timeline. Microsoft Azure has been faster to deploy new GPU generations (partly due to its OpenAI relationship), and Google has the additional complexity of balancing TPU and GPU offerings.
Expected Rubin availability on hyperscale cloud: Q1-Q2 2027
NeoCloud Operators (CoreWeave, Lambda, Crusoe, Together AI)
Neocloud operators are purpose-built for GPU compute and have consistently been first-to-market with new NVIDIA hardware. CoreWeave had H100 instances available months before AWS. Lambda Labs has built its business on rapid GPU deployment. Crusoe, which operates its own power infrastructure, can provision datacenter capacity faster than traditional operators.
These operators have already signaled aggressive Rubin procurement:
- CoreWeave has announced multi-billion-dollar datacenter expansion plans that align with the Rubin timeline
- Lambda continues to expand its GPU cloud with a focus on being first to offer new NVIDIA hardware
- Crusoe has differentiated by building datacenters at stranded energy sites, which gives them a power advantage for the 1000W+ per GPU that Rubin demands
Expected Rubin availability on neoclouds: H2 2026 (within weeks of NVIDIA shipping)
On-Premise (DGX Rubin, Custom Builds)
Organizations with their own datacenter facilities can purchase DGX Rubin systems directly from NVIDIA or build custom configurations using Rubin GPUs from OEM partners (Dell, HPE, Supermicro, Lenovo). This path offers the most control but requires:
- Adequate power infrastructure (expect 40-80 kW per rack for Rubin deployments)
- Liquid cooling capability (mandatory for Rubin-class power densities)
- Procurement lead time (DGX systems have historically had 6-12 month lead times at launch)
Expected DGX Rubin availability: H2 2026 for initial orders, volume availability Q1 2027
Colocation (Equinix, QTS, Digital Realty, CyrusOne)
Colocation operators provide the physical datacenter infrastructure — power, cooling, network, physical security — while the customer owns and operates the servers. For Rubin deployments, the colocation conversation has shifted from "can you provide rack space?" to "can you provide the power density and liquid cooling we need?"
Equinix, QTS (a Blackstone portfolio company), Digital Realty, and CyrusOne are all investing heavily in high-density AI-ready colocation facilities. The key constraints:
- Power density: Traditional colocation provides 8-15 kW per rack. Rubin deployments will need 40-80 kW per rack.
- Liquid cooling: Direct-to-chip liquid cooling is becoming a prerequisite, not an option.
- Power availability: Many existing colocation facilities are power-constrained and cannot add enough utility power for large GPU deployments without multi-year infrastructure buildouts.
Expected Rubin-ready colocation availability: Varies by facility; purpose-built AI colocation sites in late 2026, retrofit of existing facilities throughout 2027.
The Datacenter Hunger: Power, Cooling, and the New Constraints
Rubin does not just raise the bar for GPU performance — it raises the bar for everything around the GPU. The datacenter infrastructure required to support Rubin-class deployments is qualitatively different from what most facilities were designed to provide.
Power: The Real Bottleneck
Each Rubin GPU is expected to consume approximately 1000W or more of power. A DGX-class system with 8 Rubin GPUs, Vera CPUs, networking, and cooling overhead could draw 12-15 kW. A rack of such systems could draw 60-80 kW. A SuperPOD configuration with hundreds of GPUs could draw megawatts.
For context, a typical enterprise datacenter rack is provisioned for 8-15 kW. A Rubin rack needs 4-8x that power density. This is not a GPU problem — it is an electrical infrastructure problem. New substations, transformers, and power distribution units are required, and those have lead times measured in years, not months.
This is why we are seeing an unprecedented convergence of AI companies and energy infrastructure:
- Microsoft has signed a deal to restart a Three Mile Island nuclear reactor for AI power
- Amazon has purchased a nuclear-powered datacenter campus from Talen Energy
- Crusoe Energy builds datacenters at stranded natural gas sites
- Google and Oracle are exploring small modular nuclear reactors (SMRs) for datacenter power
- Multiple operators are signing long-term power purchase agreements (PPAs) with renewable energy providers
Power is becoming the single largest constraint on AI infrastructure scaling, and Rubin's power requirements will intensify this dynamic.
Liquid Cooling: No Longer Optional
At 1000W per GPU, air cooling is physically inadequate. The thermal density simply exceeds what airflow through a server chassis can dissipate. Rubin makes direct-to-chip liquid cooling mandatory for any deployment at scale.
NVIDIA has been signaling this transition for multiple generations. The GB200 NVL72 was a liquid-cooled system. DGX Rubin will almost certainly be liquid-cooled only. This has cascading implications:
- Existing air-cooled datacenters cannot host Rubin at full density without retrofit
- Cooling distribution units (CDUs) must be installed in or near every row of GPU racks
- Plumbing infrastructure — chilled water supply, return loops, leak detection — must be added to facilities designed for air cooling
- Operational expertise in liquid cooling must be developed or hired
The companies that invested early in liquid cooling infrastructure (many neoclouds, some hyperscalers) will have a significant advantage in deploying Rubin at scale. Operators who have delayed this investment face a 12-18 month retrofit timeline before they can deploy Rubin at density.
Land, Permitting, and the Geographic Race
Building new AI datacenters is increasingly constrained by:
- Power availability: Regions with cheap, abundant electricity (e.g., parts of Texas, the Pacific Northwest, Scandinavia, Quebec) are seeing a gold rush of datacenter applications
- Permitting timelines: Environmental reviews, zoning approvals, and building permits can take 1-3 years
- Community opposition: Some localities are pushing back against large datacenter developments due to noise, water usage, and power grid impacts
- Water availability: Liquid cooling still requires heat rejection, typically to cooling towers that consume water. Water-scarce regions face additional constraints.
The organizations that will deploy Rubin at scale in 2026-2027 are the ones that secured land, power, and permits in 2024-2025. If you are starting a datacenter project today for Rubin, you are likely looking at a 2028 deployment at best.
NeoCloud Spending: Billions on the Line
The capital expenditures being committed to GPU infrastructure are staggering:
- CoreWeave has raised over $12 billion in debt financing and has committed to multi-billion-dollar datacenter buildouts
- Microsoft has announced over $80 billion in AI datacenter spending for its fiscal year 2025
- Meta has signaled $60+ billion in capital expenditures, a significant portion targeting GPU infrastructure
- Amazon is investing heavily in both its own custom chips (Trainium) and NVIDIA GPU capacity
These figures are not speculative — they are in SEC filings, earnings calls, and public investor presentations. Rubin represents a significant portion of the next wave of GPU procurement, and the operators who secure early allocation will have a competitive advantage in serving inference workloads to the rapidly growing market.
Economics Projection: What Rubin Changes for Cost-Per-Token
Predicting the exact pricing of unreleased hardware is inherently speculative. However, we can project Rubin economics based on historical GPU pricing trends and the architectural improvements described above. For current GPU pricing, use the InferenceBench Calculator.
Historical Pricing Context
| GPU | Launch Year | Cloud $/hr (approx) | Relative Inference Perf | Cost/Performance Index |
|---|---|---|---|---|
| A100 80GB | 2020 | $2.00-3.50 | 1.0x (baseline) | 1.0x |
| H100 80GB | 2023 | $2.50-4.00 | 2.5-3.0x | 0.4-0.5x |
| B200 192GB | 2025 | $4.00-7.00 (early) | 5-6x | 0.3-0.4x |
| Rubin 288GB | 2026 | $6.00-10.00 (projected) | 10-12x (projected) | 0.2-0.3x (projected) |
The pattern is consistent: each GPU generation costs somewhat more in absolute terms per GPU-hour, but the cost per unit of inference work drops substantially. A Rubin GPU might cost 2-3x more per hour than an H100, but it is projected to deliver 4-5x more inference throughput, resulting in a 40-60% reduction in cost-per-token compared to Hopper-class hardware.
The Total Cost Picture
Cost-per-token is only part of the story. Rubin's larger memory means fewer GPUs per model, which means:
- Fewer servers to purchase, power, cool, and maintain
- Less network infrastructure connecting multi-GPU configurations
- Simpler deployments with fewer failure domains
- Lower operational overhead for monitoring and managing fewer machines
For an organization serving a 405B-parameter model, moving from an 11-GPU H100 deployment to a projected 3-GPU Rubin deployment is not just a 3.6x reduction in GPU count. It is a fundamental simplification of the entire serving stack — fewer nodes, fewer network hops, fewer points of failure, simpler scaling. The total cost savings, including infrastructure and operations, could exceed the pure compute savings.
What Happens to H100 and Blackwell Pricing?
When Rubin ships, it will not immediately replace Hopper and Blackwell. Those GPUs will continue serving workloads for years, and their pricing will adjust:
- H100 spot pricing has already dropped significantly from its 2023 peak and will continue falling as Blackwell capacity comes online. By the time Rubin ships, H100 spot rates could be $1.00-1.50/hr.
- B200 pricing will stabilize at current levels through 2026 and then begin declining as Rubin becomes available.
- For cost-sensitive inference workloads that do not need maximum performance, H100 and B200 will remain excellent options at reduced prices.
This "trickle-down" effect is one of the most important dynamics in GPU infrastructure economics. You can monitor current pricing trends on the InferenceBench Calculator.
Timeline: The Road from Announcement to Deployment (2025-2028)
| Date | Milestone | Status |
|---|---|---|
| March 2025 | Rubin and Vera architecture announced at GTC 2025 | Confirmed |
| Q2 2025 | NVIDIA begins sampling Rubin silicon to partners | Expected |
| H1 2026 | Rubin GPU engineering samples to OEMs and hyperscalers | Expected |
| H2 2026 | Rubin general availability — DGX Rubin ships, neocloud deployments begin | Expected |
| Q4 2026 | First neocloud operators offer Rubin instances publicly | Projected |
| Q1-Q2 2027 | Hyperscale cloud providers (AWS, GCP, Azure) launch Rubin instances | Projected |
| 2027 | Rubin Ultra ships — targeting hyperscale training and largest inference workloads | Expected |
| 2027-2028 | Rubin becomes the volume GPU for new AI infrastructure deployments | Projected |
| 2028 | Next architecture (post-Rubin) expected announcement at GTC 2028 | Speculative |
Note the "Status" column. NVIDIA has publicly confirmed the GTC 2025 announcements and the general H2 2026 timeline for Rubin. The neocloud and hyperscaler deployment timelines are our projections based on historical patterns. The Rubin Ultra timeline is based on NVIDIA's public statements. The post-Rubin architecture is speculation based on NVIDIA's stated one-year cadence.
Who Should Care About Rubin and Vera
Enterprise AI Teams
If you are running model inference for your organization — whether serving an internal chatbot, processing documents, or running code generation — Rubin changes your capacity planning. Models that are expensive to serve today (405B-class, large MoE) become economically viable at smaller scale. Models that are borderline today (serving 70B with long context) become comfortable. Start planning your GPU refresh cycle now. Use the InferenceBench Workload Matcher to model your current requirements and extrapolate.
GPU Cloud Operators
Neocloud and GPU cloud operators face a critical procurement decision. Rubin allocation is not guaranteed — NVIDIA manages GPU supply carefully and prioritizes customers based on commitment size, payment terms, and strategic importance. Operators who want Rubin capacity at launch need to be in procurement conversations with NVIDIA now, securing allocation slots and preparing their datacenter infrastructure (power, cooling, networking) to receive the hardware.
The competitive dynamics are intense. Being 3-6 months later to Rubin than a competitor could mean losing customers who want the latest hardware. But over-committing to Rubin procurement before demand materializes carries financial risk. The operators who navigate this well will define the next generation of AI cloud infrastructure.
Datacenter Investors and Developers
Rubin validates the thesis that AI datacenter demand is structural, not cyclical. The power requirements per GPU continue to increase, which means every watt of datacenter power capacity is more valuable. Investors in datacenter real estate, power infrastructure, and cooling technology are betting on a multi-decade buildout cycle, and Rubin's specifications support that bet.
Key metrics to watch: power cost per kW in target markets, utility interconnection timelines, liquid cooling adoption rates, and GPU cloud pricing trends.
Model Developers
For teams building models, Rubin changes the design space. If you know your model will be deployed on Rubin-class hardware in 2027, you can make different architectural decisions today:
- Larger MoE models become practical for inference (the memory capacity eliminates the deployment barrier)
- Longer context windows can be assumed (288 GB HBM + Vera CPU memory overflow)
- Higher precision inference becomes affordable (FP8 instead of INT4, because there is enough compute and memory bandwidth)
- Multi-modal models with large vision encoders fit more comfortably in GPU memory
Autonomous Vehicle and Robotics Companies
AV companies like Waymo, Cruise (now operating under GM's direction), Aurora, and numerous robotics startups run massive inference workloads — not just for the vehicles themselves, but for the datacenter-side simulation, labeling, and model training pipelines. These workloads are growing faster than the vehicles themselves, as simulation-based validation requires running inference on billions of synthetic scenarios.
Rubin's memory capacity is particularly relevant for large multi-modal models used in driving (like NVIDIA's own Alpamayo architecture), which process multiple camera feeds simultaneously and require significant memory for both the model and the input data. You can read our benchmark of NVIDIA Alpamayo on H100 for a sense of current requirements.
Sovereign AI and Government Programs
Multiple governments worldwide are investing in domestic AI compute infrastructure — France, Japan, India, the UAE, Saudi Arabia, Singapore, Canada, and others have announced sovereign AI initiatives. These programs are procuring large GPU clusters, and Rubin will be a target procurement for the next wave of sovereign AI infrastructure. The Vera CPU's ARM architecture may also be relevant for sovereign buyers who want to reduce dependencies on x86 vendors.
How InferenceBench Is Preparing for Rubin
We are tracking the Rubin architecture closely and plan to add Rubin GPU specifications to the InferenceBench engine as soon as NVIDIA publishes confirmed specs. Here is what this means for our tools:
- Calculator: Rubin GPU profiles will be added to the GPU catalog, enabling cost and performance projections for Rubin deployments
- Workload Matcher: Users will be able to size workloads for Rubin, comparing GPU counts and configurations against current-gen hardware
- Provider Comparison: As operators begin offering Rubin instances, we will track pricing and availability across providers
- Leaderboard: Rubin inference benchmarks will be added as real benchmark data becomes available
- Training Calculator: Rubin profiles for training workloads, including the impact of HBM4 on gradient and optimizer state memory
Our goal is to have Rubin support in InferenceBench before the first cloud instances go live, so operators and enterprise teams can plan their migrations with real data.
Conclusion: The Flywheel Accelerates
NVIDIA's Rubin architecture and Vera CPU represent the next turn of a flywheel that has been accelerating for years. More compute enables larger models. Larger models drive demand for more compute. More demand justifies more investment in GPU architectures, datacenter infrastructure, and the entire AI ecosystem.
What makes Rubin particularly significant is that it attacks the memory wall — the fundamental constraint that has shaped AI infrastructure economics since the beginning of the large language model era. HBM4's capacity and bandwidth improvements, combined with Vera's coherent CPU-GPU memory, do not just make existing workloads faster. They make previously impractical configurations viable and change the economics of serving AI at scale.
For datacenter operators, the message is clear: invest in power and cooling infrastructure now, or be locked out of the next generation of AI workloads. For enterprise AI teams, the message is equally clear: plan your GPU refresh cycle with Rubin in the picture, and use tools like InferenceBench to model the cost and performance implications.
The AI infrastructure arms race is not slowing down. It is accelerating. And the organizations that prepare for Rubin today will be the ones serving AI workloads at scale tomorrow.
Start planning your GPU infrastructure with real data.
- GPU Inference Calculator — Model current costs and project future savings
- Workload Matcher — Size your models to the right GPU configuration
- Provider Comparison — Compare GPU cloud pricing across 19+ providers
- Training Calculator — Estimate fine-tuning costs and hardware requirements
Sources: NVIDIA GTC 2025 keynote (Jensen Huang, March 2025), NVIDIA official architecture announcements, public SEC filings from Microsoft, Meta, Amazon, CoreWeave S-1 filing, SK Hynix HBM4 product announcements, industry analyst reports. All projected specifications are clearly marked and based on publicly available information as of April 2026. This post does not contain material non-public information.
More articles
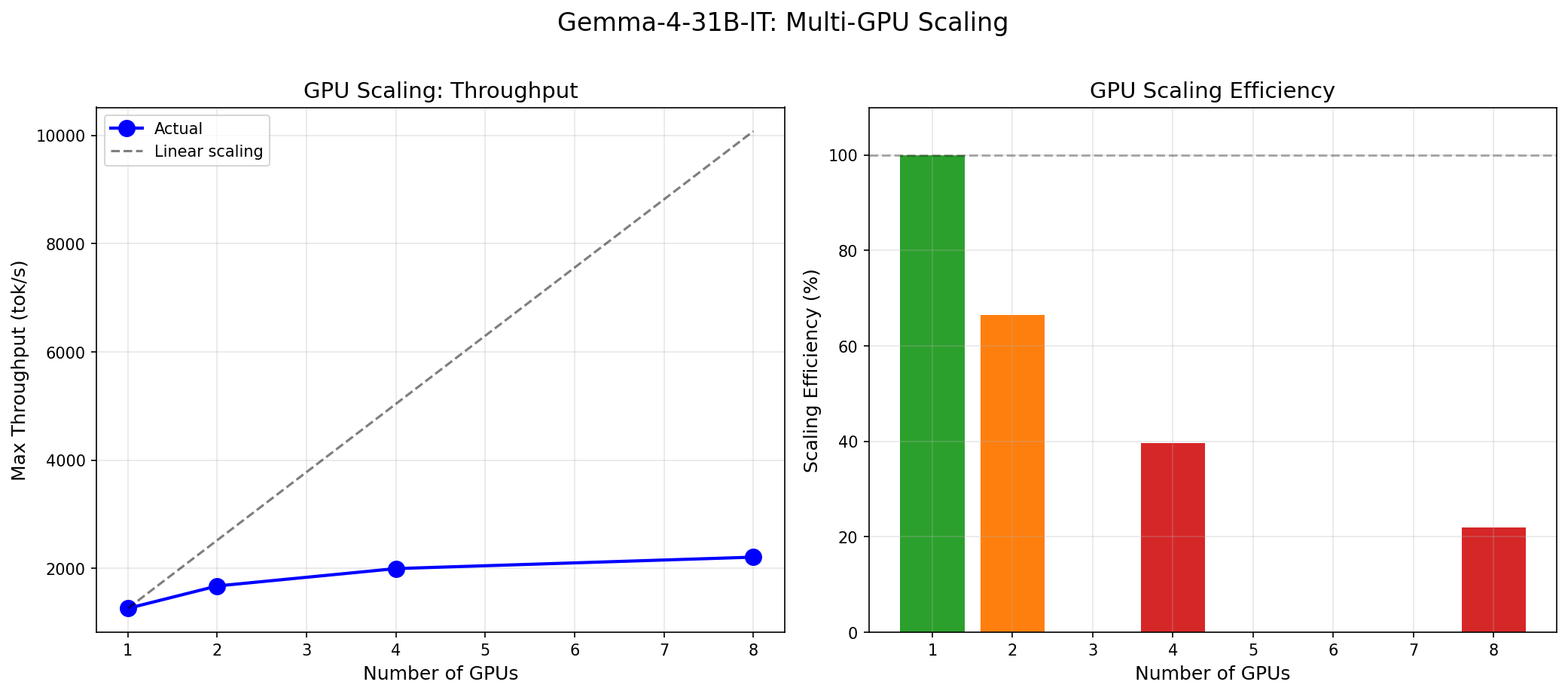
Gemma 4 vs the MoE Field: When a 31B Dense Model Wins and When It Doesn't
Gemma 4 31B scores 9.73/10 MT-Bench from 31B dense params. We compare it against Mixtral 8x22B and DeepSeek V3 on cost, latency, and quality tradeoffs.
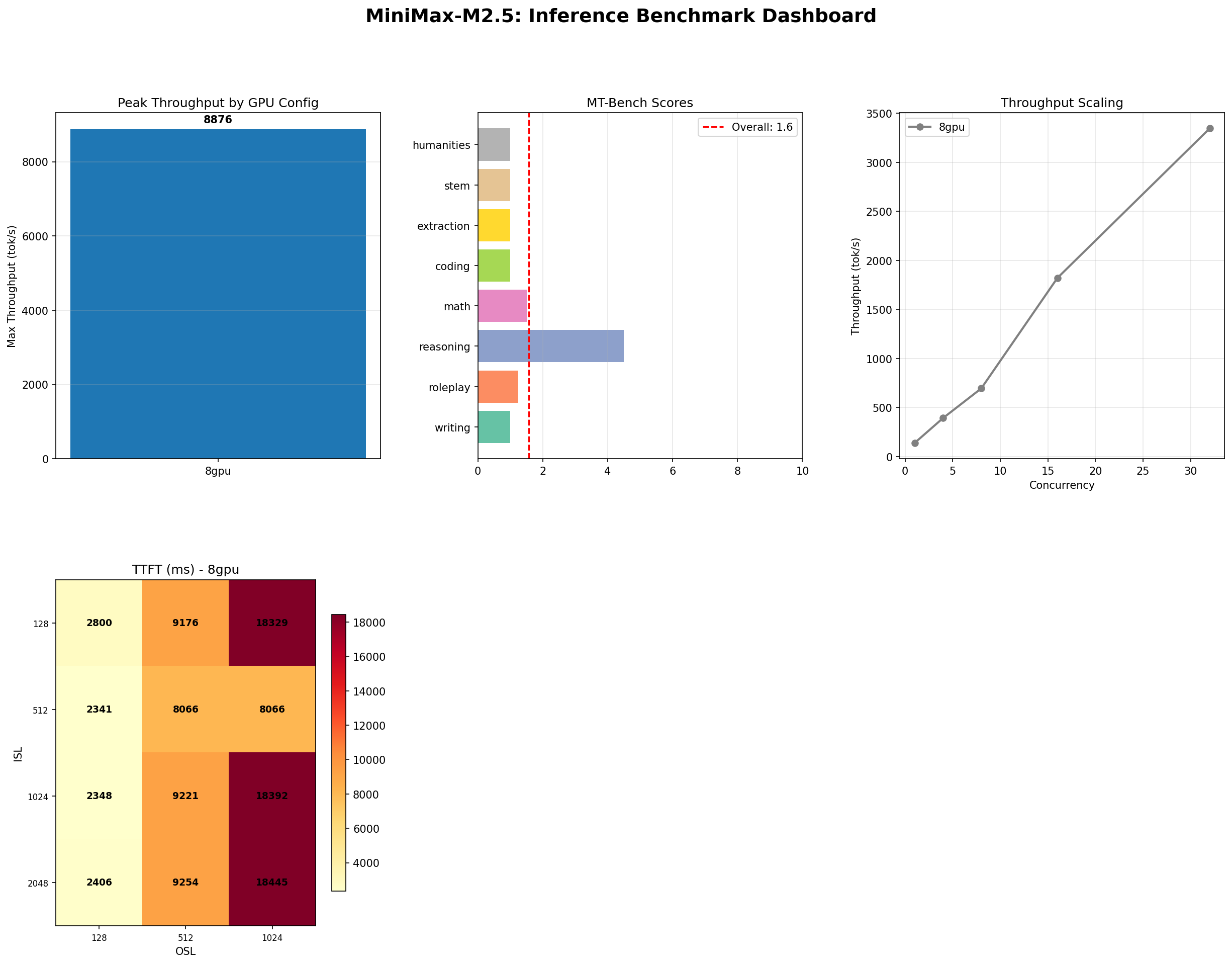
MiniMax M2.5: A 229B MoE Model That Defies Easy Judgment
MiniMax M2.5 229B MoE benchmarked on 8x H100: 8,876 tok/s peak, 100% needle-in-haystack, 87% tool use, but 1.57/10 MT-Bench. The full contradictory picture.
The GPU Memory Wall: Forecasting AI Demand to 2028
GPU memory is the defining bottleneck of AI infrastructure. We analyze the demand curve from HBM3e through HBM4E, forecast requirements to 2028, and outline strategies to stay ahead.