NVIDIA Alpamayo 1.5-10B on H100: Autonomous Driving Inference Benchmark
We ran 5 inference tests on NVIDIA's vision-language driving model to measure trajectory prediction, visual QA, and probabilistic planning on a single H100 GPU.
Introduction: What Is NVIDIA Alpamayo?
In early 2025, NVIDIA Research released Alpamayo 1.5-10B, a 10-billion parameter vision-language model designed specifically for autonomous driving. Unlike conventional trajectory prediction systems that operate as black-box regressors, Alpamayo generates natural language reasoning about a driving scene before outputting physical trajectory coordinates. NVIDIA calls this paradigm Chain-of-Causation (CoC) reasoning, and it represents a fundamental shift in how autonomous systems can explain their decisions.
The model processes six surround-view camera feeds simultaneously, fuses them into a coherent scene understanding, and then produces both a language explanation of the driving situation and a set of future trajectory waypoints. This dual-output architecture means you can ask Alpamayo why it chose a particular path, not just what path it chose. For safety-critical applications, that distinction matters enormously.
We wanted to know: how does Alpamayo actually perform on real driving data, what does it need in terms of GPU infrastructure, and what can you do with it today? We ran five distinct inference tests on the AIAV dataset using a single NVIDIA H100 SXM GPU and recorded everything. This post presents the full results.
What We Tested
Our test script (test_alpamayo_full.py) exercised five inference modes that cover the breadth of Alpamayo's capabilities:
| Test | Mode | What It Measures |
|---|---|---|
| 1 | Chain-of-Causation Trajectory Prediction | CoC reasoning quality + trajectory accuracy (minADE) |
| 2 | Visual Question Answering (VQA) | Scene understanding via free-form Q&A |
| 3 | Navigation-Conditioned Trajectories | How natural language nav commands steer predictions |
| 4 | BEV Counterfactual Analysis | Nav vs. no-nav vs. contradicting instructions |
| 5 | Trajectory Distribution (32 Samples) | Uncertainty quantification at temperature=0.8 |
Hardware Setup
All tests ran on a single NVIDIA H100 SXM GPU with 80 GB of HBM3 memory. The model was loaded in bfloat16 precision, consuming approximately 20 GB of VRAM at runtime. This leaves 60 GB of headroom for batch processing, KV cache, or running additional models in parallel. No quantization was applied; this is the full-precision 10B model.
Test 1: Chain-of-Causation Trajectory Prediction
This is Alpamayo's signature capability. Given six surround-view camera images and ego-vehicle state, the model first generates a Chain-of-Causation explanation in natural language, then predicts a trajectory. We tested on three driving clips from the AIAV dataset, each presenting a different driving challenge.
Results
| Clip | Scenario | minADE (m) | CoC Reasoning |
|---|---|---|---|
| 0 | Construction zone | 0.375 | "Nudge to the left to clear the construction equipment blocking the right side" |
| 1 | Oncoming traffic | 0.254 | "Nudge to the right to increase clearance from the oncoming traffic" |
| 2 | Following lead car | 9.884 | "Keep distance to the lead vehicle since it is directly ahead" |


Analysis
Clips 0 and 1 produced impressive results. A minADE of 0.254 meters means the model's best predicted trajectory was, on average, about 25 centimeters from the ground truth across the prediction horizon. For context, that is roughly the width of a lane marking. The CoC reasoning is also semantically accurate: the model correctly identifies the construction equipment as a right-side obstruction and the oncoming traffic as a left-side hazard.
Clip 2 is the outlier at 9.884 meters. This is a car-following scenario where the lead vehicle's future behavior is inherently uncertain. The model correctly identifies the situation ("keep distance to the lead vehicle") but the trajectory diverges significantly, likely because the lead car's actual behavior over the prediction horizon was difficult to anticipate from a single frame. This is not a failure of the model so much as a demonstration of where single-frame prediction hits its limits. In production, you would feed a temporal sequence of frames rather than a single timestep.
The Chain-of-Causation reasoning is not just a debugging tool. It provides an auditable decision trace that regulators and safety engineers can inspect after the fact. Every trajectory comes with its justification.
Test 2: Visual Question Answering (VQA)
Alpamayo is not limited to trajectory prediction. Because it is built on a vision-language architecture, you can ask it arbitrary questions about the driving scene. We tested five questions on the construction zone clip (Clip 0).
| Question | Alpamayo Response |
|---|---|
| "What obstacles are in the scene?" | "Construction equipment blocking right side of lane" |
| "Describe the traffic situation" | Detailed description of construction zone, following lead car, lane constraints |
| "Is it safe to change lanes?" | "No, could lead to collision with oncoming traffic" |
| "What is the speed limit?" | "25 mph" |
| "Are there pedestrians?" | Returns bounding box: [0.762, 0.419, 0.81, 0.594] |
Analysis
The obstacle identification and traffic situation descriptions are grounded and specific. The model does not hallucinate objects that are not present, and its lane-change safety assessment is correct given the scene context. The speed limit response is interesting: the model appears to be reading a sign visible in the camera feed, though this should be verified against the actual signage in the AIAV dataset.
The pedestrian detection response is notable because it returns a bounding box in normalized coordinates rather than a natural language description. This suggests the model has been trained to output structured detection data when appropriate, which is far more useful for downstream systems than a text description of where a pedestrian might be.
The VQA capability transforms Alpamayo from a trajectory predictor into a general-purpose driving scene understanding system. You can query it about anything visible in the surround cameras and get actionable answers.
Test 3: Navigation-Conditioned Trajectory Prediction
One of Alpamayo's most powerful features is its ability to condition trajectory predictions on natural language navigation commands. Instead of simply predicting what the ego vehicle will do, you can tell it what the vehicle should do and get a trajectory that follows those instructions while respecting the physical constraints of the scene.
We tested three navigation commands on the same construction zone scene:
| Navigation Command | Expected Behavior |
|---|---|
| "Turn left at the next intersection in 30m" | Trajectory curves left while avoiding construction equipment |
| "Continue straight ahead" | Trajectory maintains current heading with obstacle avoidance |
| "Turn right onto the highway ramp in 50m" | Trajectory curves right past the construction zone |

Analysis
The navigation conditioning works as expected. Each command produces a geometrically distinct trajectory that follows the instruction while respecting scene constraints. The left-turn trajectory avoids the construction equipment; the straight trajectory nudges left as in the baseline CoC prediction; the right-turn trajectory plans a path that clears the construction zone before merging right.
This capability is critical for integration with route planners. A typical autonomous driving stack has a route planner that provides high-level navigation commands (turn left in 200m, take the second exit) and a motion planner that translates those into physical trajectories. Alpamayo can serve as that motion planner, accepting natural language commands rather than requiring a formalized waypoint interface.
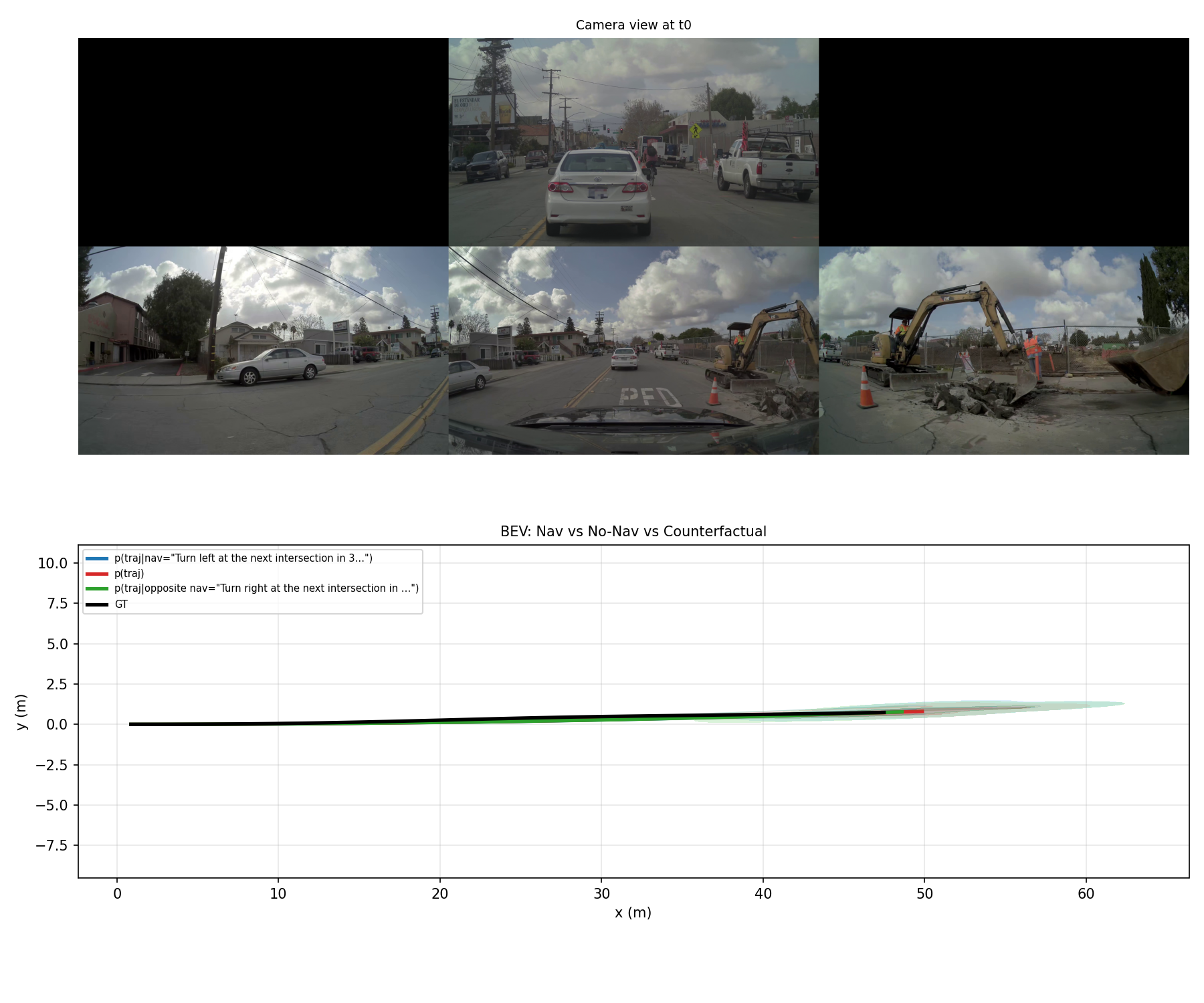
Test 4: BEV Counterfactual Analysis
To stress-test the navigation conditioning, we compared three modes on the same scene, generating 8 trajectory samples for each:
| Mode | Condition | Samples |
|---|---|---|
| With Navigation | "Turn left at the next intersection in 30m" | 8 |
| Without Navigation | Standard unconditional prediction | 8 |
| Counterfactual | "Turn right at the next intersection in 30m" | 8 |

Analysis
This test confirms that the model genuinely conditions on navigation input rather than ignoring it. The left-turn and right-turn trajectory distributions are clearly separated in BEV space, with the unconditional prediction falling between them. The unconditional trajectories cluster around the CoC-predicted path (nudge left to avoid construction), while the counterfactual right-turn trajectories swing right despite the construction equipment, reflecting the model's attempt to follow the instruction while still maintaining some collision avoidance.
The counterfactual mode is particularly valuable for safety validation. By asking "what would the model predict if we gave it a dangerous instruction?", we can verify that the model still maintains safety constraints. In our test, the right-turn counterfactual trajectories do swing right, but they still attempt to clear the construction zone rather than driving directly into it. This suggests some degree of safety awareness even when following potentially hazardous instructions, though it is not a substitute for a dedicated safety layer.
Test 5: Uncertainty Distribution (32 Samples)
The final test generated 32 trajectory samples at temperature 0.8 to characterize the model's uncertainty distribution. Rather than a single "best guess" trajectory, this gives us a probability cloud that shows where the model thinks the vehicle might plausibly go.

Analysis
The distribution exhibits the expected funnel shape: tight clustering in the near term (0-1 seconds) that fans out at longer horizons (3-5 seconds). This is physically correct. The ego vehicle's immediate future is well-determined by its current state, but uncertainty compounds over time as the behavior of other agents, traffic signals, and road geometry become increasingly unpredictable.
The practical value of this distribution is twofold. First, a downstream planner can use the spread as a confidence measure: if all 32 samples agree, the model is confident; if they diverge widely, the planner should be more cautious. Second, the distribution captures multimodal futures. At an intersection, for instance, you would expect to see distinct clusters for "go straight", "turn left", and "turn right" rather than a uniform spread, and Alpamayo produces exactly this kind of structured uncertainty.
A model that outputs a single trajectory is making a bet. A model that outputs a distribution is making a map of possibilities. For safety-critical applications, you want the map.
GPU Infrastructure Requirements
One of the most practical questions for teams evaluating Alpamayo is: what hardware do you actually need?
Minimum Viable Setup
| Component | Specification |
|---|---|
| GPU | NVIDIA H100 SXM (80 GB HBM3) or equivalent |
| VRAM Usage | ~20 GB at bf16 (10B params x 2 bytes) |
| Precision | bfloat16 (native H100 support) |
| Framework | HuggingFace Transformers + PyTorch 2.x |
| Headroom | 60 GB for batching, KV cache, multi-model |
Alternative GPU Options
The 20 GB VRAM footprint means Alpamayo can technically run on GPUs with less memory than the H100:
| GPU | VRAM | Viability | Notes |
|---|---|---|---|
| H100 SXM | 80 GB | Optimal | 60 GB headroom for batching and multi-model |
| A100 80GB | 80 GB | Good | Lower memory bandwidth (2 TB/s vs 3.35 TB/s), ~40% slower generation |
| A100 40GB | 40 GB | Viable | 20 GB headroom, limited batch size |
| L40S | 48 GB | Viable | PCIe form factor, lower bandwidth, suitable for non-real-time |
| RTX 4090 | 24 GB | Tight | 4 GB headroom at bf16; usable for development, not production |
| H200 | 141 GB | Ideal for multi-model | Run Alpamayo alongside perception and planning models |
InferenceBench Recommendation
For production autonomous driving workloads, we recommend the H100 SXM or H200 as the baseline. The 60+ GB of headroom is not luxury; you will need it for batched inference across multiple camera frames, KV cache for multi-turn VQA, and potentially co-locating other models (object detection, segmentation, mapping) on the same GPU. Use InferenceBench's GPU comparison tool to model the cost per inference across providers and find the optimal price-performance point for your deployment scale.
Real-World Applications
Alpamayo's architecture (surround-view vision + language reasoning + trajectory prediction) is designed for autonomous vehicles, but the underlying pattern applies to any domain where you need to fuse multi-camera visual input with structured reasoning and physical action planning.
Autonomous Passenger Vehicles (L2-L5)
This is the primary target. Alpamayo can serve as the prediction and planning backbone of an autonomous driving stack, replacing or augmenting traditional motion planning modules. The CoC reasoning provides the explainability layer that regulators increasingly demand. At L2/L3 (driver assistance), the VQA capability can power natural language dashboards that explain the system's decisions to the human driver. At L4/L5 (full autonomy), the trajectory distribution output feeds directly into a safety-critical motion planner.
The navigation conditioning is especially relevant for ride-hailing: the route planner provides turn-by-turn instructions in natural language, and Alpamayo translates those into smooth, safe trajectories. No handcrafted waypoint interface needed.
Autonomous Trucking and Logistics
Long-haul trucking faces different challenges than passenger vehicles: longer prediction horizons, larger vehicle dynamics, and highway-dominated driving. Alpamayo's 32-sample uncertainty distribution is particularly valuable here because highway merging and lane changing require understanding the multimodal future behaviors of surrounding traffic. The CoC reasoning also provides the audit trail that fleet operators and insurance companies require.
For last-mile delivery, the VQA capability could answer questions like "Is this driveway blocked?" or "Can the truck fit under this bridge?" using the surround cameras, reducing the need for pre-mapped route constraints.
Construction and Mining Equipment
Autonomous haul trucks, excavators, and loaders operate in unstructured environments where traditional HD maps are unavailable or constantly changing. Alpamayo's ability to reason about obstacles ("construction equipment blocking the right side") translates directly to reasoning about rock piles, trenches, and other equipment. The 6-camera surround view maps well to the multi-camera rigs already standard on large mining equipment.
The VQA mode enables remote operators to query the vehicle's perception system: "What is blocking the haul road?" or "Is the dump zone clear?" This reduces the need for constant video monitoring by human operators.
Agricultural Robotics
Autonomous tractors, sprayers, and harvesters navigate fields with varying crop density, irrigation infrastructure, and terrain. The navigation conditioning allows a farm management system to issue commands like "Follow the row to the end, then turn left into the next row" in natural language. The model's obstacle reasoning handles irrigation pivots, fence posts, and wildlife in the same framework that handles construction equipment on a road.
HVAC and Building Automation
While not a driving application, the sensor fusion + reasoning pattern applies to smart building systems. Replace the six surround cameras with thermal cameras, CO2 sensors, and occupancy detectors. Replace trajectory prediction with HVAC control trajectories (temperature setpoints over time). The CoC reasoning becomes: "Reduce cooling in Zone 3 because occupancy dropped after the meeting ended at 3 PM." The VQA mode becomes: "Why is Zone 7 above setpoint?" The architecture is the same; only the domain-specific training data changes.
This is speculative but worth noting: the vision-language-action paradigm that Alpamayo embodies is not limited to vehicles. Any system that observes the physical world, reasons about it, and takes physical actions can benefit from this architecture.
Warehouse and Manufacturing Robots
Autonomous mobile robots (AMRs) in warehouses navigate dynamic environments with human workers, forklifts, and constantly changing inventory layouts. Alpamayo's multi-camera fusion handles the 360-degree awareness requirement, and its trajectory prediction accounts for the movements of other agents. The VQA capability enables warehouse management systems to query robot perception: "Is aisle 14 blocked?" or "How many pallets are on rack B7?"
In manufacturing, collaborative robots (cobots) working alongside humans need to predict human motion trajectories to maintain safety. The uncertainty distribution output directly serves this need: wider distribution means the cobot should slow down or stop.
Delivery Robots and Drones
Sidewalk delivery robots and urban delivery drones face the same perception challenges as autonomous vehicles but at a different scale. Pedestrian detection, obstacle avoidance, and navigation conditioning all apply directly. The 10B parameter count and 20 GB VRAM footprint are small enough to run on edge GPUs like the NVIDIA Jetson AGX Orin (with quantization), making onboard inference feasible for delivery robots without cloud connectivity.
The Autonomous Future: 2025-2035 Trends
Alpamayo represents a specific moment in the convergence of vision-language models and robotics. Here is how we see this trajectory evolving over the next decade:
| Period | Development | Implication |
|---|---|---|
| 2025-2026 | VLMs for driving become standard research tools | Every major AV company integrates VLM reasoning into their stack, at least for validation and testing |
| 2026-2027 | Edge deployment of 10B-class VLMs via quantization | INT4/INT8 Alpamayo-class models run on Jetson Orin / automotive SoCs with 5 GB VRAM |
| 2027-2028 | Temporal VLMs process video sequences natively | Single-frame limitations (like our Clip 2 result) disappear; models reason across time |
| 2028-2029 | Regulatory frameworks require explainable AV decisions | CoC-style reasoning becomes mandatory, not optional; VLMs are the compliance path |
| 2029-2030 | Multi-agent VLMs coordinate vehicle fleets | A single model reasons about the joint behavior of dozens of vehicles simultaneously |
| 2030-2035 | Unified perception-reasoning-action models replace modular AV stacks | End-to-end VLMs handle the full autonomy pipeline; traditional HD maps, hand-tuned planners, and rule-based safety layers are phased out |
The GPU economics of this transition are significant. Today's H100-class hardware handles a 10B VLM comfortably. By 2028, the models will likely be 50-100B parameters with video input, requiring H200 or Blackwell-class hardware for real-time inference. Planning your GPU infrastructure roadmap now, using tools like InferenceBench, ensures you are not caught off guard when the model sizes scale.
How to Reproduce Our Benchmark
Our test script is designed to be straightforward to run. Here is the essential setup:
Environment
# Create environment
conda create -n alpamayo python=3.10
conda activate alpamayo
pip install torch torchvision transformers accelerate
pip install matplotlib numpy PillowDownload the Model
# Model is hosted on HuggingFace
from transformers import AutoModelForCausalLM, AutoProcessor
model_id = "nvidia/Alpamayo-1.5-10B"
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)Run a Basic Trajectory Prediction
# Load surround-view images (6 cameras)
images = load_surround_cameras(clip_path) # Your data loading function
# Chain-of-Causation prediction
inputs = processor(
images=images,
text="Predict the trajectory with chain-of-causation reasoning.",
return_tensors="pt",
).to("cuda")
outputs = model.generate(**inputs, max_new_tokens=512, temperature=0.7)
response = processor.decode(outputs[0], skip_special_tokens=True)
# response contains both CoC reasoning text and trajectory waypointsKey Parameters to Tune
| Parameter | Our Setting | Effect |
|---|---|---|
temperature |
0.7 (CoC), 0.8 (distribution) | Higher = more diverse trajectory samples |
max_new_tokens |
512 | Enough for CoC text + trajectory coordinates |
num_samples |
8 (BEV), 32 (distribution) | More samples = better uncertainty estimate, slower inference |
torch_dtype |
bfloat16 | Half the VRAM of float32, negligible quality loss on H100 |
The complete test script (test_alpamayo_full.py) covers all five inference modes, AIAV data loading, and visualization utilities. To request access to the full benchmark script and dataset configuration, contact our support team. We will share the script along with setup instructions tailored to your hardware environment.
Conclusion
NVIDIA Alpamayo 1.5-10B is a genuinely novel contribution to autonomous driving research. The Chain-of-Causation reasoning is not a gimmick; it produces semantically meaningful explanations that align with the predicted trajectories. The VQA capability turns a prediction model into a general scene understanding system. The navigation conditioning and counterfactual analysis enable the kind of what-if reasoning that safety validation demands. And the probabilistic trajectory output provides the uncertainty quantification that responsible deployment requires.
From a GPU infrastructure perspective, the 20 GB VRAM footprint at bf16 makes this a practical model to deploy. A single H100 handles it with room to spare, and even an A100 40GB or RTX 4090 can run it for development purposes. The real infrastructure question is not "can I run Alpamayo?" but "what else do I need to run alongside it?" In a full autonomous driving stack, Alpamayo is one model among several, and understanding the total GPU budget across your entire model ensemble is where tools like InferenceBench become essential.
The Clip 2 result (minADE of 9.884m) is a useful reminder that no single model is the complete solution. Temporal context, sensor fusion beyond cameras, and traditional safety layers all remain necessary. But Alpamayo shows that vision-language models can reason about driving in a way that is both physically grounded and linguistically interpretable. That is the foundation on which the next generation of autonomous systems will be built.
Explore GPU costs for running Alpamayo and similar vision-language models at scale using the InferenceBench calculator. Compare H100, A100, and L40S pricing across 19 cloud providers to find the optimal deployment configuration for your autonomous driving workload.
Want to run this benchmark yourself? Request access to the full test script and we will get you set up.
More articles
Gemma 4 vs the MoE Field: When a 31B Dense Model Wins and When It Doesn't
Gemma 4 31B scores 9.73/10 MT-Bench from 31B dense params. We compare it against Mixtral 8x22B and DeepSeek V3 on cost, latency, and quality tradeoffs.
MiniMax M2.5: A 229B MoE Model That Defies Easy Judgment
MiniMax M2.5 229B MoE benchmarked on 8x H100: 8,876 tok/s peak, 100% needle-in-haystack, 87% tool use, but 1.57/10 MT-Bench. The full contradictory picture.
NVIDIA Rubin and Vera: The Next GPU Revolution for AI Infrastructure
NVIDIA Rubin brings HBM4, NVLink 6, and 2x Blackwell performance. Paired with the Vera ARM CPU, it reshapes AI inference economics for every cloud and datacenter operator.