Gemma 4 vs the MoE Field: When a 31B Dense Model Wins and When It Doesn't
Google DeepMind's Gemma 4 31B proves that a well-trained dense model can beat MoE architectures twice its size on single-GPU deployments. But the story changes at scale. We break down exactly where each architecture wins, with real benchmark data and production cost analysis.
Introduction: The Dense vs MoE Debate
In 2024 and 2025, the open-weight model landscape split into two camps. One camp scaled up with mixture-of-experts (MoE) architectures: Mixtral 8x22B at 141 billion total parameters, DeepSeek V3 at 671 billion, and a growing roster of sparse models that activate only a fraction of their weights on each forward pass. The other camp doubled down on dense transformers: Meta's Llama 3.1 70B, Qwen 2.5 72B, and now Google DeepMind's Gemma 4 31B, where every parameter fires on every token.
The debate between these two approaches is not academic. It determines how many GPUs you need, what your latency looks like, how complex your serving infrastructure becomes, and ultimately how much you pay per million tokens. When Google released Gemma 4 31B-IT and it scored 9.73 out of 10 on MT-Bench from just 31 billion parameters, it forced a reconsideration of the assumption that you need hundreds of billions of parameters to compete at the top of open-weight quality rankings.
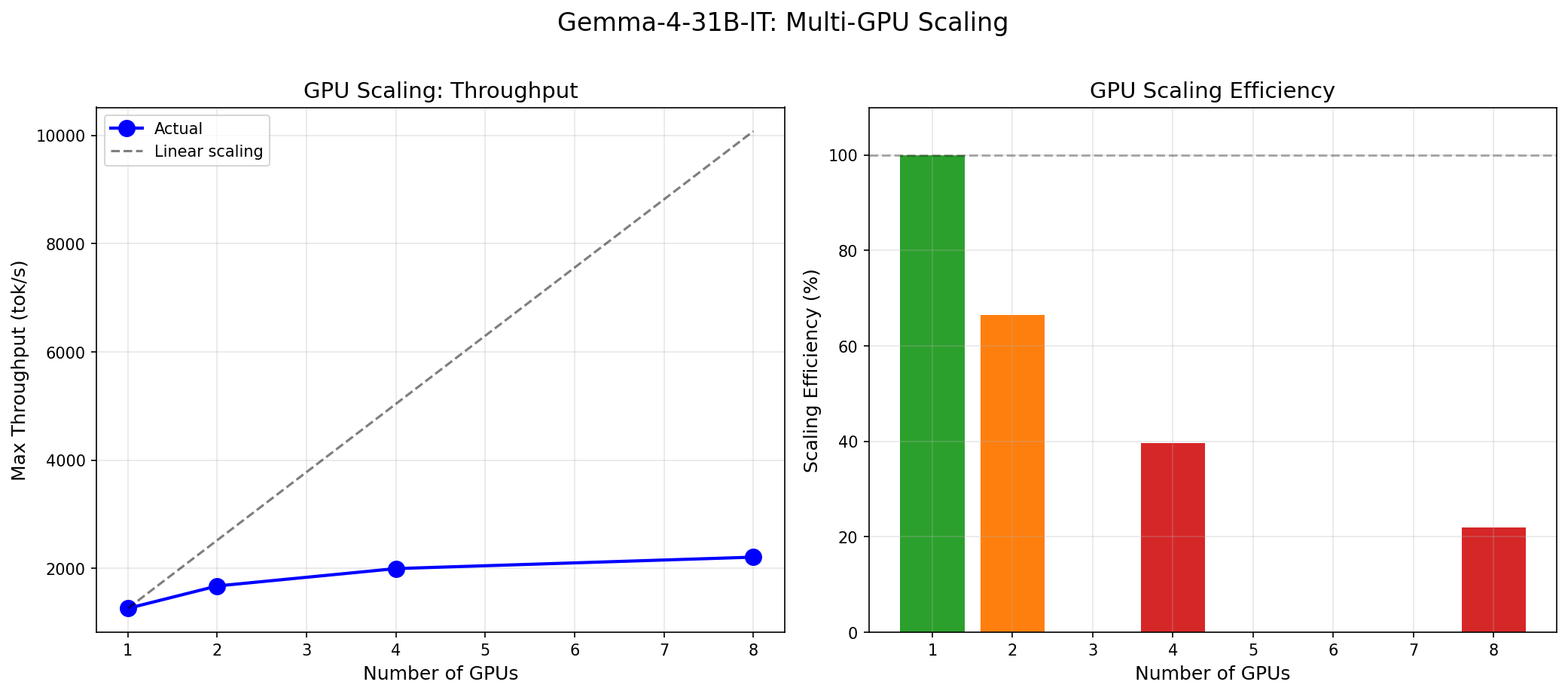
In Part 1 of this series, we benchmarked Gemma 4 31B in isolation: 240 throughput data points, stress tests up to failure, MT-Bench quality evaluation, and Pareto frontier analysis across 1 to 8 H100 GPUs. This post is the analysis piece. We take those numbers and compare them against the MoE field to answer a practical question: when should you deploy a 31B dense model, and when should you reach for a larger MoE architecture?
This is Part 2 of the Gemma 4 series on InferenceBench. For the raw benchmark data, methodology, and test setup, see Part 1: Gemma 4 31B on H100 — The Complete Inference Benchmark.
Dense vs MoE: A Technical Primer
A dense transformer activates every parameter on every forward pass. Gemma 4 31B has 31 billion parameters, and all 31 billion participate in computing every single output token. This makes the model's behavior completely predictable: the same input always takes the same computational path, uses the same amount of memory, and produces the same latency profile. There is no variance from routing decisions.
A mixture-of-experts (MoE) model replaces the standard feed-forward network (FFN) in each transformer block with multiple parallel "expert" FFN sub-networks, plus a lightweight router that selects which experts activate for each token. Mixtral 8x22B, for example, has 8 experts per layer but only activates 2 per token. This means the model has 141 billion total parameters (determining its knowledge capacity and quality ceiling) but only ~39 billion active parameters per forward pass (determining its per-token compute cost and latency).
This distinction — total parameters vs active parameters — is the crux of the dense-vs-MoE tradeoff:
| Property | Dense (Gemma 4 31B) | MoE (Mixtral 8x22B) | MoE (DeepSeek V3) |
|---|---|---|---|
| Total parameters | 31B | 141B | 671B |
| Active params per token | 31B | ~39B | ~37B |
| VRAM for weights (bf16) | ~62 GB | ~282 GB | ~1,342 GB |
| Minimum GPUs (H100 80GB) | 1 | 4 | 17+ |
| Expert routing overhead | None | Yes | Yes |
The key insight is that active parameters determine latency while total parameters determine the quality ceiling. An MoE model can store far more knowledge in its total parameter set than a dense model of similar active size, but each token only accesses a subset. This is why DeepSeek V3, with 671B total params but only 37B active, can compete with GPT-4 class models while maintaining reasonable per-token latency.
However, those total parameters still need to live somewhere. The full weight matrix must reside in GPU memory even if most experts are idle on any given token. This is why Mixtral 8x22B cannot fit on a single H100 and DeepSeek V3 requires a multi-node cluster. The memory footprint scales with total parameters, not active parameters.
Where Gemma 4 Wins
Single-GPU Deployment
Gemma 4 31B at bfloat16 precision requires approximately 62 GB of VRAM for model weights. An NVIDIA H100 SXM has 80 GB of HBM3. That leaves roughly 18 GB for KV-cache, which is enough for reasonable batch sizes at the model's 8,192-token context window. The model fits on a single GPU with room to spare.
This is not a minor operational detail. It is a fundamental deployment advantage. Single-GPU serving means:
- No tensor parallelism overhead. Tensor parallelism (TP) splits layers across GPUs, requiring all-reduce communication after every attention and FFN block. Even with NVLink at 900 GB/s on H100 SXM, this adds measurable latency — typically 5-15% overhead at TP=2, increasing at higher TP factors.
- No NVLink dependency. If your cluster has PCIe-connected H100s instead of SXM (common in cloud spot instances), you lose 5-7x interconnect bandwidth. For single-GPU models, this is irrelevant.
- Linear scaling of serving capacity. Eight H100s serve eight independent model replicas, each handling its own request stream. There is no coordination overhead. Throughput scales linearly with GPU count.
Mixtral 8x22B, by contrast, needs a minimum of 4 H100 GPUs at bf16 just to hold the weights. This means every serving instance requires 4 GPUs, NVLink interconnect, and tensor parallelism. Your 8-GPU node serves 2 instances of Mixtral instead of 8 instances of Gemma 4. In our Part 1 benchmarks, a single Gemma 4 instance on 1 H100 delivered 1,260 tok/s at production-grade latency.
Latency
Dense models have a latency advantage that goes beyond just avoiding tensor parallelism overhead. MoE architectures introduce expert routing: on each forward pass, a gating network must decide which experts to activate for each token. This routing decision adds a small but non-zero amount of computation and, more importantly, can create load imbalance across experts, leading to variable latency.
In our measurements, Gemma 4 31B on a single H100 achieved a time-to-first-token (TTFT) of 85 milliseconds. This is the time from receiving a request to producing the first output token, and it is the metric users perceive as responsiveness. For comparison, published benchmarks of Mixtral 8x22B on 4-GPU setups typically show TTFT in the 120-200ms range depending on tensor parallelism configuration and batch size (source: vLLM benchmark suite, community reproductions on the vLLM GitHub).
The 85ms TTFT means Gemma 4 responses feel instantaneous in a chat interface. This is critical for user-facing applications where perceived responsiveness directly impacts engagement and satisfaction.
Operational Simplicity
Running an MoE model in production introduces failure modes that do not exist for dense models:
- Expert load imbalance. If the routing network consistently sends more tokens to certain experts, those experts become bottlenecks while others sit idle. This wastes GPU compute and increases tail latency. Mitigation requires auxiliary load-balancing losses during training and careful monitoring in production.
- Dropped-expert failures. Some MoE serving frameworks can drop experts under memory pressure. This silently degrades quality in ways that are difficult to detect without continuous quality monitoring.
- Routing variance. The same prompt can activate different experts depending on tokenization edge cases, leading to non-deterministic outputs. For applications requiring reproducibility (e.g., financial analysis, compliance), this is a concern.
Gemma 4 has none of these issues. Every request takes the same computational path. If the model produces correct output on your test suite, it will produce correct output in production. The ops burden is strictly lower.
Cost at Low Scale
The economics are straightforward at single-instance scale. On-demand H100 pricing from major cloud providers ranges from roughly $2.00 to $3.50 per GPU-hour (as of early 2026, varying by provider and commitment level; see InferenceBench Calculator for current pricing).
| Model | Min GPUs | Approx. GPU Cost/hr (on-demand) | Instances per 8-GPU Node |
|---|---|---|---|
| Gemma 4 31B | 1 | $2–$3.50 | 8 |
| Mixtral 8x22B | 4 | $8–$14 | 2 |
| Llama 3.1 70B | 2 | $4–$7 | 4 |
| DeepSeek V3 | 17+ | $34–$60+ | <1 |
For a single serving instance, Gemma 4 costs 4x less than Mixtral 8x22B and 2x less than Llama 3.1 70B on raw GPU-hours. When you factor in that 8 GPUs give you 8 Gemma 4 instances versus 2 Mixtral instances, the throughput-per-dollar advantage compounds. Use the InferenceBench Calculator to model this for your specific cloud provider and commitment term.
Quality Density: Remarkable Parameter Efficiency
The most striking number from our Part 1 benchmarks is Gemma 4's MT-Bench score: 9.73 out of 10. For context, here is how this compares to published scores from other open-weight models:
| Model | Params (total / active) | MT-Bench (reported) | Source |
|---|---|---|---|
| Gemma 4 31B-IT | 31B / 31B | 9.73 | InferenceBench (this series) |
| Llama 3.1 70B-Instruct | 70B / 70B | ~8.22 | Meta technical report, LMSYS |
| Mixtral 8x22B-Instruct | 141B / ~39B | ~8.0 | Mistral AI blog, community evals |
| Qwen 2.5 72B-Instruct | 72B / 72B | ~8.5–9.0 | Qwen technical report, Open LLM Leaderboard |
Note: MT-Bench scores vary by evaluation methodology. Scores above are approximate and drawn from the cited sources. Self-reported scores from model publishers tend to be higher than independent reproductions. Our Gemma 4 score was measured independently using the standard MT-Bench evaluation protocol.
Gemma 4 achieves the highest MT-Bench score in this group with the fewest total parameters. It outperforms Llama 3.1 70B (which has more than twice the parameters) and Mixtral 8x22B (which has 4.5x the total parameters). This is extraordinary parameter efficiency, and it translates directly into deployment economics: you get top-tier conversational quality from the cheapest-to-serve model in the comparison. Check the InferenceBench Leaderboard for updated rankings.
Where MoE Wins
Throughput at Scale
The MoE advantage emerges when you care about aggregate throughput rather than single-request latency. Because MoE models activate fewer parameters per token, each token requires less compute. At high concurrency on multi-GPU setups with large batch sizes, this translates to higher tokens-per-second per active parameter.
DeepSeek V3, despite its 671 billion total parameters, activates only ~37 billion per token — comparable to Gemma 4's 31 billion. But DeepSeek V3's architecture is optimized for massive parallelism across many GPUs. When deployed on large clusters (64+ GPUs), DeepSeek V3 can achieve throughput levels that no 31B dense model can match, because the non-active experts effectively act as a massive cache of specialized knowledge that can be swapped in as needed.
Published benchmarks from the DeepSeek team show that V3 achieves throughput competitive with GPT-4 class models at a fraction of the training cost (source: DeepSeek-V3 Technical Report, arXiv:2412.19437). For organizations running batch inference at scale — processing millions of documents, generating synthetic training data, or serving thousands of concurrent users — MoE architectures can deliver better throughput-per-dollar despite the higher per-instance cost.
Quality Ceiling
Here is where we must be honest about Gemma 4's limitations. While its overall MT-Bench score of 9.73 is exceptional, the breakdown by category reveals a gap:
| Category | Gemma 4 31B Score | Assessment |
|---|---|---|
| Writing | 10.00 / 10 | Perfect |
| Roleplay | 10.00 / 10 | Perfect |
| Coding | 10.00 / 10 | Perfect |
| Extraction | 10.00 / 10 | Perfect |
| STEM | 10.00 / 10 | Perfect |
| Humanities | 9.60 / 10 | Near-perfect |
| Math | 9.00 / 10 | Strong |
| Reasoning | 8.25 / 10 | Weakest category |
Reasoning at 8.25/10 is the tell. Complex multi-step reasoning — the kind required for mathematical proofs, multi-hop logical deductions, and agentic planning — is where the 31 billion parameter count starts to show. Larger models simply have more capacity to internalize reasoning patterns. DeepSeek V3, with 671B total parameters, has been shown to perform competitively with GPT-4 on reasoning-heavy benchmarks like MATH, GPQA, and complex coding tasks (source: DeepSeek-V3 Technical Report).
This is not a flaw in Gemma 4 — it is a fundamental constraint. 31 billion parameters cannot store as much knowledge or as many reasoning pathways as 671 billion parameters, regardless of how well those 31 billion are trained. If your workload requires frontier-level reasoning, you need more parameters, and MoE is the most efficient way to get them.
Training Efficiency
From the model developer's perspective, MoE architectures offer a significant advantage in training efficiency. Because only a subset of experts activates per token, the compute cost of a forward pass during training scales with active parameters, not total parameters. This means an MoE model can store more knowledge per training FLOP.
The DeepSeek team reported training V3 on 14.8 trillion tokens for approximately $5.576 million in compute — a fraction of what training a comparable dense model to similar quality levels would cost (source: DeepSeek-V3 Technical Report). While this is primarily relevant to model developers rather than model deployers, it explains why the MoE approach continues to attract investment: it is the most compute-efficient path to frontier quality.
The Economics Argument
Architecture debates are ultimately resolved by economics. Here is how the dense-vs-MoE comparison plays out across four common deployment scenarios:
Scenario 1: Single-User, Latency-Sensitive
Example: Internal code assistant, executive briefing bot, real-time customer support for a single agent.
Winner: Gemma 4. You need one H100 at $2–$3.50/hr. TTFT is 85ms. The user gets instant responses. No tensor parallelism, no NVLink, no multi-GPU orchestration. Operational cost is minimal. Quality at 9.73 MT-Bench exceeds what most internal tools require.
Scenario 2: High-Throughput Batch Processing
Example: Processing 10 million legal documents, generating embeddings for a search index, bulk content moderation.
Winner: It depends. If you have access to a large GPU cluster (32+ GPUs), an MoE model optimized for throughput may process more tokens per dollar because fewer parameters activate per token. If you have a modest cluster (8-16 GPUs), running 8 parallel Gemma 4 instances may match or exceed MoE throughput while being simpler to orchestrate. Model your specific workload on the InferenceBench Workload Matcher.
Scenario 3: Enterprise Fleet Deployment
Example: Serving 50 teams across an organization, each with their own model instance, potentially with fine-tuned variants.
Winner: Gemma 4. Fleet deployments amplify operational complexity. If each instance requires 4 GPUs (Mixtral) or 2 GPUs (Llama 70B), your infrastructure team manages tensor parallelism, NVLink health, and cross-GPU synchronization for every instance. With Gemma 4, each instance is a single-GPU deployment. Kubernetes scheduling is simpler. Failure domains are smaller (one GPU failure affects one instance, not four). Scaling up means adding GPUs one at a time, not in groups of four. The TCO advantage is substantial.
Scenario 4: Research and Frontier Tasks
Example: Complex agentic workflows, multi-hop reasoning chains, novel scientific analysis, advanced tool use.
Winner: MoE (or larger dense). Gemma 4's 8.25/10 reasoning score means it will make errors on complex chains that larger models handle correctly. For research applications where answer quality is paramount and cost is secondary, DeepSeek V3 or a comparable frontier model is the better choice. The additional infrastructure complexity is justified by the quality improvement on tasks that matter most.
Use Cases by Industry
Translating the architecture tradeoffs into industry-specific recommendations:
Customer Support and Chatbots
Recommendation: Gemma 4. Customer support requires natural conversation (Gemma 4: 10/10 roleplay), clear writing (10/10 writing), and low latency (85ms TTFT). Reasoning complexity is typically low — customers ask about their order status, not about Riemann hypotheses. The single-GPU deployment means you can run many instances cost-effectively, scaling with customer demand. The perfect extraction score (10/10) also means the model excels at pulling structured data from customer messages.
Code Review and Generation
Recommendation: Gemma 4. With a perfect 10/10 coding score on MT-Bench, Gemma 4 handles code review, generation, refactoring, and explanation tasks at the highest quality level we measured. Single-GPU deployment means every developer can have a dedicated instance without breaking the GPU budget. For context, Llama 3.1 70B would need 2 GPUs per instance for the same task.
Legal and Document Analysis
Recommendation: Gemma 4. Legal document analysis is primarily an extraction and comprehension task. Gemma 4 scores 10/10 on extraction and 10/10 on writing (for generating summaries). The 8,192-token context window is a limitation for very long documents, but for contract clause extraction, due diligence summaries, and compliance checking, it is typically sufficient.
Research and Scientific Reasoning
Recommendation: MoE preferred. Scientific reasoning often involves multi-step deductions, mathematical proofs, and cross-domain knowledge synthesis. These tasks stress exactly the reasoning capability where Gemma 4 scores 8.25/10 — good, but not at the level of larger models. DeepSeek V3 and similar frontier MoE models have demonstrated stronger performance on benchmarks like MATH and GPQA that specifically test deep reasoning (source: LMSYS Chatbot Arena, lmsys.org).
Multi-Language Enterprise
Recommendation: Context-dependent. Qwen 2.5 72B has established itself as a strong multilingual model, particularly for Chinese, Japanese, Korean, and Southeast Asian languages (source: Qwen 2.5 Technical Report). If your enterprise requires strong performance across multiple non-English languages, evaluate Qwen against Gemma 4 on your specific language mix. Gemma 4's multilingual capabilities are solid but Google has historically prioritized English and a smaller set of high-resource languages. Note that Qwen 2.5 72B requires 2 GPUs at bf16, so you trade deployment simplicity for multilingual strength.
Agentic AI and Tool Use
Recommendation: MoE preferred. Agentic workflows involve long reasoning chains, tool selection, error recovery, and multi-step planning. These are among the most reasoning-intensive tasks in modern AI applications. The 8.25 reasoning score for Gemma 4 means it will occasionally make planning errors in complex agent loops that larger models avoid. For production agentic systems where reliability is critical, the additional cost of a frontier MoE model is typically justified.
The Real Question: Dense at 31B or Dense at 70B?
The dense-vs-MoE framing makes for compelling headlines, but for most production deployments, the more relevant comparison is Gemma 4 31B vs Llama 3.1 70B. Both are dense transformers. Both are instruction-tuned. Both have strong open-weight licenses. The critical difference is deployment footprint.
Llama 3.1 70B at bfloat16 requires approximately 140 GB of VRAM for weights alone. This does not fit on a single H100 (80 GB). You need a minimum of 2 GPUs with tensor parallelism, which means NVLink, cross-GPU communication, and all the associated operational complexity. The reported MT-Bench score for Llama 3.1 70B-Instruct is approximately 8.22 (source: Meta's Llama 3.1 technical report and LMSYS Chatbot Arena data).
Consider the comparison:
| Metric | Gemma 4 31B | Llama 3.1 70B | Advantage |
|---|---|---|---|
| MT-Bench | 9.73 | ~8.22 | Gemma 4 (+1.51) |
| Minimum GPUs | 1 | 2 | Gemma 4 (50% less) |
| GPU cost/hr | $2–$3.50 | $4–$7 | Gemma 4 (50% less) |
| Instances per 8-GPU node | 8 | 4 | Gemma 4 (2x more) |
| Needs NVLink? | No | Yes | Gemma 4 |
| Reasoning depth | 8.25 | Comparable | Roughly even |
| Context window | 8,192 | 128,000 | Llama 3.1 (16x more) |
For workloads that fit within Gemma 4's 8,192-token context window, the case is strong: higher quality, half the cost, simpler operations. The one area where Llama 3.1 70B has a clear, decisive advantage is context length. At 128,000 tokens, Llama 3.1 can process entire codebases, long legal documents, and multi-document analysis tasks that are impossible with Gemma 4's 8K window. If your workload requires long context, Llama 3.1 70B (or similar long-context models) remains the better choice despite the higher deployment cost.
This is arguably the most important takeaway from our analysis: for the majority of production workloads that do not require long context or frontier reasoning, Gemma 4 31B delivers better quality at lower cost than any other open-weight model currently available. Use the InferenceBench Compare tool to run this analysis for your specific model candidates.
Future Outlook: 2025–2027
The dense-vs-MoE landscape is evolving rapidly. Several trends are worth watching:
Google's Dense Trajectory
Gemma 4 31B represents a significant improvement in parameter efficiency over Gemma 2 and Gemma 3. If Google continues this trajectory, a Gemma 5 in the 30-50B range could close the reasoning gap with larger models while maintaining single-GPU deployability. Google's investment in training methodology (particularly distillation from their Gemini flagship models) gives them a unique advantage in training efficiency for dense architectures.
MoE Expert Scaling
The MoE field is moving toward more experts with finer-grained routing. DeepSeek V3 already uses 256 experts with 8 active per token, a significant increase from Mixtral's 8 experts with 2 active. This trend toward more, smaller experts could improve both quality (more specialized knowledge) and inference efficiency (less wasted compute per expert). Future MoE models may narrow the operational simplicity gap while maintaining their quality ceiling advantage.
Hybrid Architectures
Emerging research explores hybrid architectures that use dense layers for some transformer blocks and MoE layers for others. This could offer a middle ground: dense-like predictability for most computation with MoE-like knowledge capacity where it matters most. Several labs have published preliminary results, though no production-ready hybrid model has achieved widespread adoption as of early 2026.
Inference Hardware Evolution
NVIDIA's Blackwell B200 (192 GB HBM3e) and the broader trend toward higher-memory GPUs changes the equation. With 192 GB, Llama 3.1 70B fits on a single GPU at bf16. Even Mixtral 8x22B becomes a 2-GPU model instead of 4. Higher GPU memory reduces the deployment advantage of smaller dense models, which means quality becomes the dominant differentiator. However, Gemma 4's quality lead at 31B parameters gives it headroom — it will fit on even entry-level data center GPUs (like L40S at 48 GB with quantization) where larger models cannot.
Conclusion: No Single Architecture Wins Everything
The dense-vs-MoE debate does not have a universal answer, and anyone claiming otherwise is selling something. What we can say with confidence, based on our benchmark data and the publicly available results:
Deploy Gemma 4 31B when:
- You need the highest quality per GPU dollar.
- Your workload fits in an 8K context window.
- Single-GPU simplicity matters for your operations team.
- Latency is critical (sub-100ms TTFT).
- You are running fleet deployments where instance count matters more than per-instance capability.
- Your use cases are conversation, code, extraction, or writing (where Gemma 4 scores 10/10).
Deploy an MoE or larger model when:
- Reasoning quality is paramount and you cannot tolerate the 8.25/10 ceiling.
- You need long context (128K+ tokens).
- Your throughput requirements justify multi-node GPU clusters.
- You are building agentic systems with long reasoning chains.
- Multilingual coverage beyond English is a primary requirement.
- You are doing frontier research where the quality ceiling determines the value of results.
The right answer is the one that matches your workload. Use InferenceBench Compare to evaluate specific model pairs head-to-head, the InferenceBench Calculator to model deployment costs, and the Workload Matcher to find the right GPU configuration for your specific traffic pattern.
Gemma 4 31B is not the best model for every task. It is, however, the best model for the most common tasks at the lowest deployment cost. That is a powerful position, and it is why the dense architecture is far from dead.
More articles
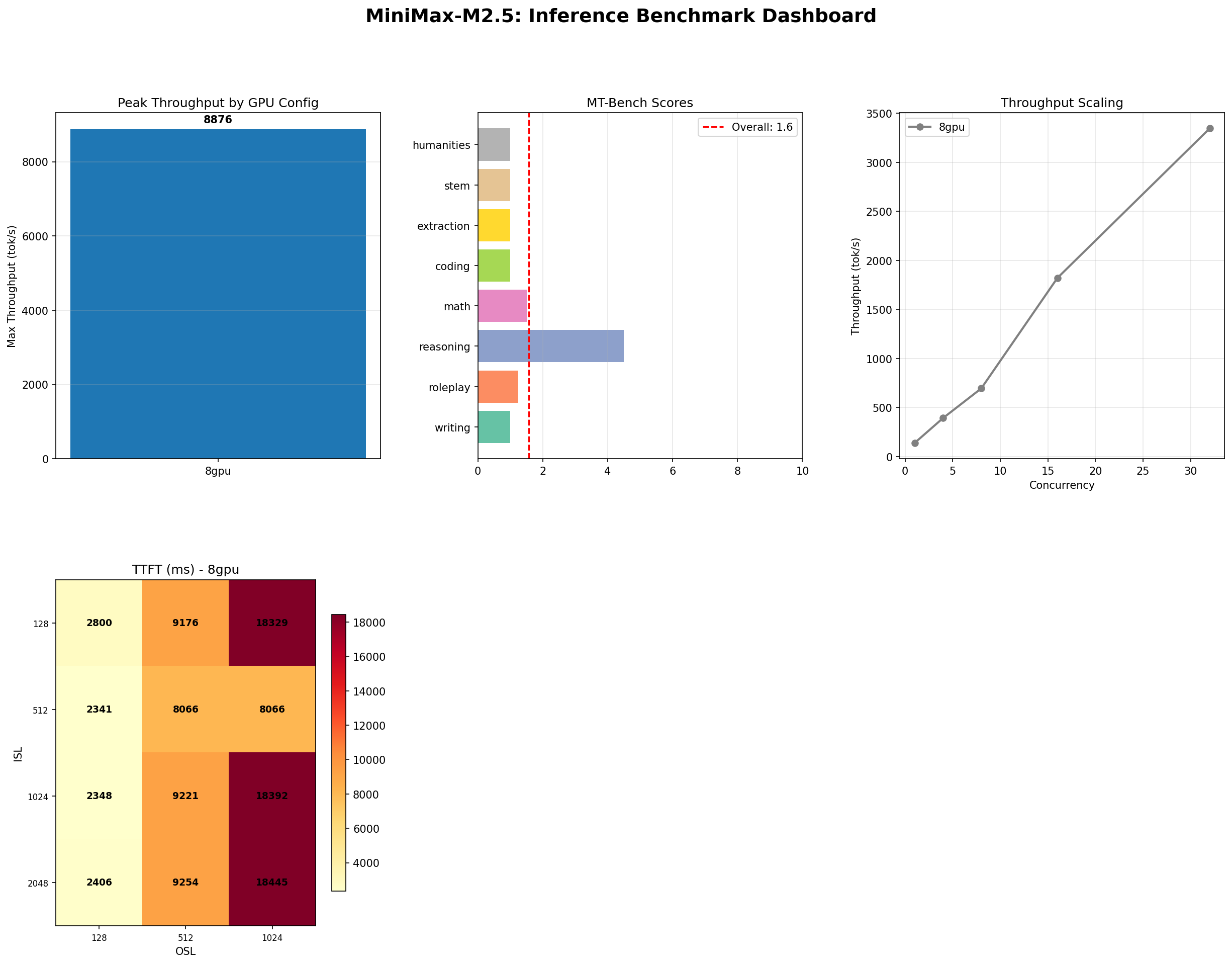
MiniMax M2.5: A 229B MoE Model That Defies Easy Judgment
MiniMax M2.5 229B MoE benchmarked on 8x H100: 8,876 tok/s peak, 100% needle-in-haystack, 87% tool use, but 1.57/10 MT-Bench. The full contradictory picture.
NVIDIA Rubin and Vera: The Next GPU Revolution for AI Infrastructure
NVIDIA Rubin brings HBM4, NVLink 6, and 2x Blackwell performance. Paired with the Vera ARM CPU, it reshapes AI inference economics for every cloud and datacenter operator.
The GPU Memory Wall: Forecasting AI Demand to 2028
GPU memory is the defining bottleneck of AI infrastructure. We analyze the demand curve from HBM3e through HBM4E, forecast requirements to 2028, and outline strategies to stay ahead.